Odlučujuća pravila u teoriji prepoznavanja uzoraka. Primjeri problema prepoznavanja uzoraka
Poglavlje 3: Analitički pregled metoda prepoznavanja uzoraka i donošenja odluka
Teorija prepoznavanja uzoraka i automatizacija upravljanja
Glavne zadaće adaptivnog prepoznavanja uzoraka
Prepoznavanje je informacijski proces koji provodi neki informacijski pretvarač (inteligentni informacijski kanal, sustav za prepoznavanje) koji ima ulaz i izlaz. Ulaz sustava je informacija o tome koje karakteristike imaju prikazani objekti. Izlaz sustava prikazuje informacije o tome kojim klasama (generaliziranim slikama) pripadaju prepoznati objekti.
Prilikom izrade i rada automatiziranog sustava za prepoznavanje uzoraka rješavaju se brojni problemi. Razmotrimo ukratko i jednostavno ove zadatke. Imajte na umu da različiti autori imaju iste formulacije ovih problema, a sam skup se ne podudara, budući da u određenoj mjeri ovisi o specifičnom matematičkom modelu na kojem se temelji ovaj ili onaj sustav prepoznavanja. Osim toga, neki problemi u pojedinim modelima prepoznavanja nemaju rješenja te se, shodno tome, ne postavljaju.
Zadatak formalizacije predmetnog područja
U biti ovaj zadatak je zadatak kodiranja. Sastavlja se popis generaliziranih klasa kojima mogu pripadati određene implementacije objekata, kao i popis karakteristika koje ti objekti, u načelu, mogu posjedovati.
Zadatak formiranja uzorka za obuku
Skup za obuku je baza podataka koja sadrži opise specifičnih implementacija objekata u jeziku značajki, dopunjenu informacijama o pripadnosti tih objekata određenim klasama prepoznavanja.
Zadatak obuke sustava za prepoznavanje
Uzorak za obuku koristi se za formiranje generaliziranih slika klasa prepoznavanja na temelju generalizacije informacija o tome koje značajke imaju objekti uzorka za obuku koji pripadaju ovoj klasi i drugim klasama.
Problem smanjivanja dimenzija prostora obilježja
Nakon osposobljavanja sustava za prepoznavanje (dobivanje statistike o distribuciji učestalosti obilježja po klasama), postaje moguće za svako obilježje odrediti njegovu vrijednost za rješavanje problema prepoznavanja. Nakon toga, najmanje vrijedne značajke mogu se ukloniti iz sustava značajki. Zatim se sustav za prepoznavanje mora ponovno uvježbati, budući da se kao rezultat uklanjanja nekih obilježja mijenja statistika raspodjele preostalih obilježja po klasama. Ovaj proces se može ponoviti, tj. biti iterativan.
Zadatak prepoznavanja
Prepoznaju se objekti prepoznatog uzorka koji se, posebice, mogu sastojati od jednog objekta. Uzorak za prepoznavanje formira se slično kao onaj za obuku, ali ne sadrži podatke o pripadnosti objekata klasama, jer se upravo to utvrđuje tijekom procesa prepoznavanja. Rezultat prepoznavanja svakog objekta je distribucija ili popis svih klasa prepoznavanja u silaznom redoslijedu prema stupnju sličnosti prepoznatog objekta s njima.
Problem kontrole kvalitete prepoznavanja
Nakon prepoznavanja može se utvrditi njegova adekvatnost. Za objekte uzorka za obuku to se može učiniti odmah, jer se za njih jednostavno zna kojoj klasi pripadaju. Za ostale objekte ovi podaci se mogu dobiti naknadno. U svakom slučaju, može se utvrditi stvarna prosječna vjerojatnost pogreške za sve klase prepoznavanja, kao i vjerojatnost pogreške pri dodjeljivanju prepoznatog objekta određenoj klasi.
Rezultati prepoznavanja moraju se tumačiti uzimajući u obzir dostupne informacije o kvaliteti prepoznavanja.
Problem prilagodbe
Ako se kao rezultat postupka kontrole kvalitete utvrdi da ona nije zadovoljavajuća, tada se opisi netočno prepoznatih objekata mogu kopirati iz uzorka prepoznavanja u onaj za obuku, nadopuniti odgovarajućim klasifikacijskim informacijama i koristiti za preoblikovanje pravila odlučivanja. , tj. uzeti u obzir. Štoviše, ako ti objekti ne pripadaju postojećim klasama prepoznavanja, što bi mogao biti razlog njihovog pogrešnog prepoznavanja, tada se ovaj popis može proširiti. Kao rezultat toga, sustav za prepoznavanje se prilagođava i počinje adekvatno klasificirati te objekte.
Inverzni problem prepoznavanja
Zadatak prepoznavanja je da za određeni objekt, na temelju njegovih poznatih karakteristika, sustav utvrdi njegovu pripadnost nekoj prethodno nepoznatoj klasi. U inverznom problemu prepoznavanja, naprotiv, za zadanu klasu prepoznavanja sustav utvrđuje koja su svojstva najkarakterističnija za objekte ove klase, a koja nisu (ili koji objekti uzorka za obuku pripadaju ovoj klasi).
Problemi klasterske i konstruktivne analize
Klasteri su takve skupine objekata, klasa ili obilježja da su unutar svakog klastera što sličniji, a između različitih klastera što je moguće više različiti.
Konstrukt (u kontekstu koji se razmatra u ovom odjeljku) je sustav suprotstavljenih klastera. Dakle, u određenom smislu, konstrukti su rezultat klaster analize klastera.
U klaster analizi kvantitativno se mjeri stupanj sličnosti i razlike između objekata (klasa, obilježja), a te se informacije koriste za klasifikaciju. Rezultat klaster analize je razvrstavanje objekata u klastere. Ova se klasifikacija može prikazati u obliku semantičkih mreža.
Zadatak kognitivne analize
U kognitivnoj analizi informacije o sličnostima i razlikama između klasa ili karakteristika zanimaju istraživača same po sebi, a ne da bi ih koristile za klasifikaciju, kao u klasterskoj i konstruktivnoj analizi.
Ako je ista značajka karakteristična za dvije klase raspoznavanja, to pridonosi sličnosti tih dviju klasa. Ako za jednu od klasa ova značajka nije karakteristična, onda to doprinosi razlici.
Ako dva obilježja međusobno koreliraju, tada se u određenom smislu mogu smatrati jednim obilježjem, a ako su antikorelirani, onda različitima. Uzimajući u obzir ovu okolnost, prisutnost različitih karakteristika u različitim klasama također daje određeni doprinos njihovoj sličnosti i različitosti.
Rezultati kognitivne analize mogu se prikazati u obliku kognitivnih dijagrama.
Metode prepoznavanja uzoraka i njihove karakteristike
Načela klasifikacije metoda prepoznavanja uzoraka
Prepoznavanje uzoraka odnosi se na problem konstruiranja i primjene formalnih operacija na numeričkim ili simboličkim reprezentacijama objekata u stvarnom ili idealnom svijetu, čiji rezultati odražavaju odnose ekvivalencije između tih objekata. Odnosi ekvivalencije izražavaju pripadnost procijenjenih objekata bilo kojoj klasi, koja se smatra neovisnom semantičkom jedinicom.
Prilikom konstruiranja algoritama za prepoznavanje, klase ekvivalencije može specificirati istraživač koji koristi vlastite smislene ideje ili koristi vanjske dodatne informacije o sličnostima i razlikama objekata u kontekstu problema koji se rješava. Zatim govore o "prepoznavanju kod učitelja". Inače, t.j. Kada automatizirani sustav rješava problem klasifikacije bez upotrebe vanjskih informacija o obuci, govorimo o automatskoj klasifikaciji ili "nenadziranom prepoznavanju". Većina algoritama za prepoznavanje uzoraka zahtijeva korištenje vrlo značajne računalne snage, koju može osigurati samo računalna tehnologija visokih performansi.
Razni autori (Yu.L. Barabash, V.I. Vasiliev, A.L. Gorelik, V.A. Skripkin, R. Duda, P. Hart, L.T. Kuzin, F.I. Peregudov, F.P. Tarasenko, F.E. Temnikov, J. Tu, R. Gonzalez, P. Winston, K. Fu, Ya.Z. Tsypkin, itd.) daju drugačiju tipologiju metoda prepoznavanja uzoraka. Neki autori razlikuju parametarske, neparametarske i heurističke metode, drugi identificiraju skupine metoda na temelju povijesno utemeljenih škola i trendova u ovom području. Primjerice, u radu koji daje akademski pregled metoda prepoznavanja koristi se sljedeća tipologija metoda prepoznavanja uzoraka:
- metode temeljene na principu razdvajanja;
- statističke metode;
- metode izgrađene na temelju “potencijalnih funkcija”;
- metode za izračunavanje rejtinga (glasovanje);
- metode temeljene na iskaznom računu, posebice na aparatu logičke algebre.
Ova se klasifikacija temelji na razlici u formalnim metodama prepoznavanja uzoraka i stoga izostavlja razmatranje heurističkog pristupa prepoznavanju, koji je dobio puni i odgovarajući razvoj u ekspertnim sustavima. Heuristički pristup temelji se na teško formalizirajućem znanju i intuiciji istraživača. U tom slučaju istraživač sam određuje koje će informacije i na koji način sustav koristiti da bi postigao traženi učinak prepoznavanja.
Slična tipologija metoda prepoznavanja s različitim stupnjevima detalja nalazi se u mnogim radovima o prepoznavanju. U isto vrijeme, poznate tipologije ne uzimaju u obzir jednu vrlo značajnu karakteristiku, koja odražava specifičnost načina predstavljanja znanja o predmetnom području pomoću bilo kojeg formalnog algoritma za prepoznavanje uzoraka.
D.A. Pospelov (1990) identificira dva glavna načina prezentiranja znanja:
- intenzionalni, u obliku dijagrama veza između atributa (osobina).
- ekstenziono, uz pomoć konkretnih činjenica (predmeta, primjera).
Intenzivno predstavljanje hvata uzorke i veze koji objašnjavaju strukturu podataka. U odnosu na dijagnostičke zadatke, takva se fiksacija sastoji u definiranju operacija nad atributima (značajkama) objekata koji dovode do traženog dijagnostičkog rezultata. Intenzionalne reprezentacije implementiraju se kroz operacije na vrijednostima atributa i ne podrazumijevaju operacije na specifičnim informacijskim činjenicama (objektima).
S druge strane, ekstenzivne reprezentacije znanja povezane su s opisom i fiksacijom specifičnih objekata iz predmetnog područja i implementirane su u operacije čiji su elementi objekti kao integralni sustavi.
Može se povući analogija između intenzijskih i ekstenzijskih prikaza znanja i mehanizama koji leže u osnovi aktivnosti lijeve i desne hemisfere ljudskog mozga. Ako desnu hemisferu karakterizira holistički prototipski prikaz okolnog svijeta, tada lijeva hemisfera djeluje s obrascima koji odražavaju veze između atributa ovog svijeta.
Dva temeljna načina predstavljanja znanja opisana gore omogućuju nam da predložimo sljedeću klasifikaciju metoda prepoznavanja uzoraka:
- intenzionalne metode temeljene na operacijama sa značajkama.
- ekstenzijske metode temeljene na operacijama s objektima.
Posebno treba istaknuti da je postojanje upravo ove dvije (i samo dvije) skupine metoda prepoznavanja: onih koje operiraju znakovima i onih koje operiraju objektima, duboko prirodno. S ove točke gledišta, niti jedna od ovih metoda, odvojeno jedna od druge, ne omogućuje nam da formiramo adekvatan odraz predmetnog područja. Prema autorima, između ovih metoda postoji odnos komplementarnosti u smislu N. Bohra, stoga bi perspektivni sustavi prepoznavanja trebali omogućiti implementaciju obje ove metode, a ne bilo koje od njih.
Dakle, klasifikacija metoda prepoznavanja koju je predložio D. A. Pospelov temelji se na temeljnim obrascima koji leže u osnovi ljudskog načina spoznaje općenito, što ga stavlja u potpuno poseban (privilegiran) položaj u usporedbi s drugim klasifikacijama, koje u ovoj pozadini izgledaju lakše i lakše. Umjetna.
Intenzivne metode
Posebnost intenzionalnih metoda je da koriste različite karakteristike značajki i njihove veze kao elemente operacija pri konstrukciji i primjeni algoritama za prepoznavanje uzoraka. Takvi elementi mogu biti pojedinačne vrijednosti ili intervali vrijednosti obilježja, prosječne vrijednosti i varijance, matrice odnosa obilježja itd., na kojima se izvode radnje, izražene u analitičkom ili konstruktivnom obliku. Pritom se objekti u ovim metodama ne smatraju integralnim informacijskim jedinicama, već djeluju kao indikatori za procjenu interakcije i ponašanja njihovih atributa.
Skupina intenzijskih metoda za prepoznavanje uzoraka je opsežna, a njezina je podjela na podklase u određenoj mjeri uvjetna.
Metode temeljene na procjeni gustoće distribucije vrijednosti obilježja
Ove metode prepoznavanja uzoraka posuđene su iz klasične teorije statističkih odluka, u kojoj se objekti proučavanja smatraju realizacijama višedimenzionalne slučajne varijable raspoređene u prostoru značajki prema nekom zakonu. Temelje se na Bayesovoj shemi odlučivanja koja se poziva na apriorne vjerojatnosti objekata koji pripadaju određenoj priznatoj klasi i uvjetne gustoće distribucije vrijednosti vektora obilježja. Ove se metode svode na određivanje omjera vjerojatnosti u različitim područjima višedimenzionalnog prostora značajki.
Skupina metoda koja se temelji na procjeni gustoće distribucije vrijednosti obilježja izravno je povezana s metodama diskriminativne analize. Bayesov pristup odlučivanju jedna je od najrazvijenijih tzv. parametarskih metoda u modernoj statistici, za koju se analitički izraz zakona distribucije (u ovom slučaju normalnog zakona) smatra poznatim, a samo mali broj parametara ( vektori prosječnih vrijednosti i matrice kovarijancije) moraju se procijeniti.
Glavne poteškoće u korištenju ovih metoda su potreba da se zapamti cijeli uzorak za obuku kako bi se izračunale procjene lokalnih gustoća distribucije vjerojatnosti i velika osjetljivost na nereprezentativnost uzorka za obuku.
Metode temeljene na pretpostavkama o klasi funkcija odlučivanja
U ovoj skupini metoda opći oblik funkcije odlučivanja smatra se poznatim i specificira funkcional njezine kvalitete. Na temelju ovog funkcionala, najbolja aproksimacija funkcije odlučivanja nalazi se korištenjem sekvence učenja. Najčešći su prikazi funkcija odlučivanja u obliku linearnih i generaliziranih nelinearnih polinoma. Funkcional kvalitete pravila odlučivanja obično je povezan s greškom klasifikacije.
Glavna prednost metoda temeljenih na pretpostavkama o klasi funkcija odlučivanja je jasnoća matematičke formulacije problema prepoznavanja kao problema traženja ekstrema. Raznolikost metoda u ovoj skupini objašnjava se širokim rasponom funkcionala kvalitete pravila odlučivanja i korištenih algoritama pretraživanja ekstrema. Generalizacija algoritama koji se razmatraju, koji uključuju, posebice, Newtonov algoritam, algoritme perceptronskog tipa itd., je metoda stohastičke aproksimacije.
Mogućnosti algoritama pretraživanja gradijentnog ekstremuma, posebno u skupini linearnih pravila odlučivanja, prilično su dobro proučene. Konvergencija ovih algoritama je dokazana samo za slučaj kada su prepoznate klase objekata prikazane u prostoru značajki kompaktnim geometrijskim strukturama.
Dovoljno visoka kvaliteta pravila odlučivanja može se postići pomoću algoritama koji nemaju striktan matematički dokaz konvergencije rješenja globalnom ekstremumu. Takvi algoritmi uključuju veliku skupinu heurističkih programskih postupaka koji predstavljaju smjer evolucijskog modeliranja. Evolucijsko modeliranje bionička je metoda posuđena iz prirode. Temelji se na korištenju poznatih mehanizama evolucije kako bi se proces smislenog modeliranja složenog objekta zamijenio fenomenološkim modeliranjem njegove evolucije. Poznati predstavnik evolucijskog modeliranja u prepoznavanju uzoraka je metoda grupnog obračuna argumenata (MGUA). Osnova GMDH je princip samoorganizacije, a GMDH algoritmi reproduciraju shemu masovne selekcije.
Međutim, postizanje praktičnih ciljeva u ovom slučaju nije popraćeno izvlačenjem novih znanja o prirodi objekata koji se prepoznaju. Mogućnost izdvajanja tog znanja, posebice znanja o mehanizmima interakcije atributa (značajki), ovdje je temeljno ograničena zadanom strukturom takve interakcije, fiksiranom u odabranom obliku funkcija odlučivanja.
Booleove metode
Logičke metode prepoznavanja uzoraka temelje se na aparatu logičke algebre i omogućuju rad s informacijama sadržanim ne samo u pojedinačnim značajkama, već iu kombinacijama vrijednosti značajki. U ovim metodama, vrijednosti bilo kojeg atributa smatraju se elementarnim događajima.
U najopćenitijem obliku, logičke metode mogu se okarakterizirati kao vrsta pretraživanja kroz uzorak za obuku logičkih obrazaca i formiranje određenog sustava logičkih pravila odlučivanja (na primjer, u obliku konjunkcija elementarnih događaja), svaki od koji ima svoju težinu. Skupina logičkih metoda je raznolika i uključuje metode različite složenosti i dubine analize. Za dihotomne (Booleove) značajke popularni su takozvani klasifikatori nalik na stablo, slijepa metoda testiranja, algoritam “Bark” itd.
Algoritam “Kora”, kao i druge logičke metode prepoznavanja uzoraka, prilično je računski zahtjevan, budući da je potrebna potpuna pretraga pri odabiru konjunkcija. Stoga se pri korištenju logičkih metoda postavljaju visoki zahtjevi za učinkovitu organizaciju računskog procesa, a te metode dobro rade s relativno malim dimenzijama prostora značajki i samo na snažnim računalima.
Lingvističke (strukturne) metode
Lingvističke metode prepoznavanja uzoraka temelje se na korištenju posebnih gramatika koje generiraju jezike koji se mogu koristiti za opisivanje skupa svojstava prepoznatih objekata.
Za različite klase objekata utvrđuju se neizvedeni (atomski) elementi (podslike, atributi) i mogući odnosi među njima. Gramatika se odnosi na pravila za konstruiranje objekata iz tih neizvedenih elemenata.
Dakle, svaki objekt je zbirka neizvedenih elemenata, međusobno "povezanih" na ovaj ili onaj način ili, drugim riječima, "rečenicom" nekog "jezika". Posebno bih istaknuo vrlo značajnu ideološku vrijednost ove misli.
Sintaktičkim raščlanjivanjem "rečenice" određuje se njezina sintaktička "ispravnost" ili, ekvivalentno, može li neka fiksna gramatika koja opisuje klasu generirati postojeći opis objekta.
Međutim, zadatak rekonstruiranja (definiranja) gramatika iz određenog skupa iskaza (rečenica – opisa objekata) koji generiraju dati jezik teško je formalizirati.
Ekstenzivne metode
U metodama ove skupine, za razliku od intenzionalnog smjera, svakom proučavanom objektu se u većoj ili manjoj mjeri pridaje samostalno dijagnostičko značenje. U svojoj srži, ove su metode bliske kliničkom pristupu, koji ljude ne promatra kao lanac objekata rangiranih po jednom ili drugom pokazatelju, već kao cjelovite sustave, od kojih je svaki individualan i ima posebnu dijagnostičku vrijednost. Takav pažljiv odnos prema objektima istraživanja ne dopušta isključivanje ili gubljenje informacija o svakom pojedinom objektu, što se događa pri korištenju metoda intenzionog usmjerenja koje koriste objekte samo za otkrivanje i bilježenje obrazaca ponašanja njihovih atributa.
Glavne operacije u prepoznavanju uzoraka korištenjem razmatranih metoda su operacije određivanja sličnosti i razlika objekata. Objekti u navedenoj skupini metoda igraju ulogu dijagnostičkih presedana. Štoviše, ovisno o uvjetima konkretnog zadatka, uloga pojedinog presedana može varirati u najširim granicama: od glavne i određujuće do vrlo neizravnog sudjelovanja u procesu priznavanja. Zauzvrat, uvjeti problema mogu zahtijevati sudjelovanje različitog broja dijagnostičkih presedana za uspješno rješenje: od jednog u svakoj prepoznatoj klasi do pune veličine uzorka, kao i različite metode za izračunavanje mjera sličnosti i razlike objekata. . Ovi zahtjevi objašnjavaju daljnju podjelu ekstenzijskih metoda na potklase.
Metoda usporedbe s prototipom
Ovo je najjednostavnija metoda ekstenzivnog prepoznavanja. Koristi se, primjerice, u slučaju kada se prepoznate klase prikazuju u prostoru značajki kompaktnim geometrijskim skupinama. U ovom slučaju, obično je središte geometrijskog grupiranja klase (ili objekt najbliži središtu) odabrano kao točka prototipa.
Za klasificiranje nepoznatog objekta, pronalazi se njemu najbliži prototip, a objekt pripada istoj klasi kao i ovaj prototip. Očito, ovom metodom se ne generiraju generalizirane slike klasa.
Kao mjera blizine mogu se koristiti različite vrste udaljenosti. Često se za dihotomna obilježja koristi Hammingova udaljenost, koja je u ovom slučaju jednaka kvadratu euklidske udaljenosti. U ovom slučaju, pravilo odlučivanja za klasificiranje objekata je ekvivalentno linearnoj funkciji odlučivanja.
Tu činjenicu treba posebno istaknuti. Jasno pokazuje vezu između prototipa i atributnog prikaza informacija o strukturi podataka. Koristeći gornji prikaz, može se, na primjer, smatrati bilo koja tradicionalna mjerna ljestvica, koja je linearna funkcija vrijednosti dihotomnih karakteristika, kao hipotetski dijagnostički prototip. S druge strane, ako nam analiza prostorne strukture prepoznatih klasa omogućuje izvođenje zaključka o njihovoj geometrijskoj kompaktnosti, onda je dovoljno svaku od tih klasa zamijeniti jednim prototipom, što je zapravo ekvivalentno linearnom dijagnostičkom modelu.
U praksi je, naravno, situacija često drugačija od opisanog idealiziranog primjera. Istraživač koji namjerava primijeniti metodu prepoznavanja temeljenu na usporedbi s prototipovima dijagnostičkih klasa suočava se s teškim problemima.
Prije svega, to je izbor mjere (metrike) blizine, koja može značajno promijeniti prostornu konfiguraciju rasporeda objekata. Drugo, samostalan problem je analiza višedimenzionalnih struktura eksperimentalnih podataka. Oba ova problema posebno su akutna za istraživača u uvjetima visoke dimenzionalnosti prostora obilježja, karakteristične za stvarne probleme.
k metoda najbližih susjeda
Metoda k-najbližeg susjeda za rješavanje problema diskriminativne analize prvi je put predložena davne 1952. godine. To je kako slijedi.
Pri klasificiranju nepoznatog objekta pronalazi se zadani broj (k) njemu geometrijski najbližih u prostoru značajki drugih objekata (najbližih susjeda) s već poznatim članstvom u prepoznatim klasama. Odluka o dodjeli nepoznatog objekta određenoj dijagnostičkoj klasi donosi se analizom informacija o toj poznatoj pripadnosti njegovih najbližih susjeda, na primjer, korištenjem jednostavnog brojanja glasova.
U početku se metoda k-najbližih susjeda smatrala neparametrijskom metodom za procjenu omjera vjerojatnosti. Za ovu metodu dobivene su teorijske procjene njezine učinkovitosti u usporedbi s optimalnim Bayesovim klasifikatorom. Dokazano je da vjerojatnosti asimptotske pogreške za metodu k-najbližih susjeda premašuju pogreške Bayesova pravila za najviše dva puta.
Kada koristi metodu k-najbližih susjeda za prepoznavanje uzoraka, istraživač mora riješiti težak problem odabira metrike za određivanje blizine dijagnosticiranih objekata. Ovaj problem u uvjetima visoke dimenzionalnosti prostora značajki izuzetno je pogoršan zbog dostatne složenosti ove metode, što postaje značajno čak i za računala visokih performansi. Stoga je ovdje, baš kao iu metodi usporedbe s prototipom, potrebno riješiti kreativni problem analize višedimenzionalne strukture eksperimentalnih podataka kako bi se smanjio broj objekata koji predstavljaju dijagnostičke klase.
Potreba za smanjenjem broja objekata u uzorku za obuku (dijagnostički presedani) je nedostatak ove metode, jer smanjuje reprezentativnost uzorka za obuku.
Algoritmi za izračunavanje ocjena (“glasovanje”)
Načelo rada algoritama za izračun procjene (ABO) je izračunavanje prioriteta (rezultata sličnosti) koji karakteriziraju "blizinu" prepoznatih i referentnih objekata prema sustavu ansambala obilježja, koji je sustav podskupova danog skupa obilježja .
Za razliku od svih prethodno razmatranih metoda, algoritmi za izračunavanje procjena rade s opisima objekata na potpuno nov način. Za ove algoritme, objekti postoje istovremeno u vrlo različitim podprostorima prostora značajki. ABO klasa dovodi ideju korištenja značajki do logičnog završetka: budući da nije uvijek poznato koje su kombinacije značajki najinformativnije, tada se u ABO stupanj sličnosti objekata izračunava usporedbom svih mogućih ili specifičnih kombinacija značajke uključene u opise objekata.
Korištene kombinacije značajki (potprostora) autori nazivaju skupovima potpore ili skupovima parcijalnih opisa objekata. Uvodi se koncept generalizirane blizine između prepoznatog objekta i objekata uzorka za obuku (s poznatom klasifikacijom), koji se nazivaju referentnim objektima. Ova blizina je predstavljena kombinacijom blizine prepoznatog objekta s referentnim objektima, izračunatom na skupovima djelomičnih opisa. Dakle, ABO je proširenje metode k-najbližih susjeda, u kojoj se blizina objekata razmatra samo u jednom zadanom prostoru značajki.
Još jedno proširenje ABO-a je da je u ovim algoritmima zadatak određivanja sličnosti i razlike objekata formuliran kao parametarski i istaknuta je faza postavljanja ABO-a na temelju skupa za obuku, pri čemu su optimalne vrijednosti unesenih parametri su odabrani. Kriterij kvalitete je pogreška prepoznavanja, a doslovno je sve parametrizirano:
- pravila za izračunavanje blizine objekata na temelju individualnih karakteristika;
- pravila za izračunavanje blizine objekata u podprostorima obilježja;
- stupanj važnosti određenog referentnog objekta kao dijagnostičkog presedana;
- značaj doprinosa svakog referentnog skupa obilježja konačnoj procjeni sličnosti prepoznatog objekta s bilo kojom dijagnostičkom klasom.
ABO parametri navedeni su u obliku graničnih vrijednosti i (ili) kao težine navedenih komponenti.
Teoretske mogućnosti AVO-a nisu niže od onih bilo kojeg drugog algoritma za prepoznavanje uzoraka, budući da se uz pomoć AVO-a mogu implementirati sve zamislive operacije s predmetima koji se proučavaju.
Ali, kao što to obično biva, proširenje potencijalnih mogućnosti nailazi na velike poteškoće u njihovoj praktičnoj implementaciji, posebno u fazi konstruiranja (podešavanja) algoritama ove vrste.
Neke poteškoće primijećene su ranije kada se raspravljalo o metodi k-najbližih susjeda, koja bi se mogla tumačiti kao skraćena verzija ABO. Također se može razmatrati u parametarskom obliku i smanjiti problem na pronalaženje ponderirane metrike odabranog tipa. Istodobno, već ovdje se za visokodimenzionalne probleme pojavljuju složena teorijska pitanja i problemi vezani uz organizaciju učinkovitog računskog procesa.
Za AVO, ako pokušate iskoristiti mogućnosti ovih algoritama u najvećoj mjeri, te se poteškoće višestruko povećavaju.
Navedeni problemi objašnjavaju činjenicu da je u praksi korištenje ABO za rješavanje problema visoke dimenzije popraćeno uvođenjem nekih heurističkih ograničenja i pretpostavki. Konkretno, dobro je poznat primjer korištenja ABO u psihodijagnostici, u kojem je testirana vrsta ABO, koja je zapravo ekvivalentna metodi k-najbližih susjeda.
Kolektivi pravila odlučivanja
Kako bismo dovršili naš pregled metoda prepoznavanja uzoraka, pogledajmo još jedan pristup. To su takozvani kolektivi pravila odlučivanja (DRG).
Budući da se različiti algoritmi za prepoznavanje različito manifestiraju na istom uzorku objekata, prirodno se postavlja pitanje sintetičkog pravila odlučivanja koje adaptivno koristi prednosti tih algoritama. Sintetičko pravilo odlučivanja koristi dvorazinsku shemu prepoznavanja. Na prvoj razini djeluju privatni algoritmi za prepoznavanje čiji se rezultati kombiniraju na drugoj razini u bloku sinteze. Najčešće metode takvog objedinjavanja temelje se na identificiranju područja kompetencije pojedinog algoritma. Najjednostavniji način pronalaženja područja kompetencija je apriorna podjela prostora atributa na temelju stručnih razmatranja određene znanosti (primjerice, stratificiranje uzorka prema određenom atributu). Zatim se za svako od odabranih područja izrađuje vlastiti algoritam za prepoznavanje. Druga se metoda temelji na upotrebi formalne analize za određivanje lokalnih područja prostora obilježja kao susjedstva prepoznatih objekata za koje je dokazana uspješnost bilo kojeg određenog algoritma prepoznavanja.
Najopćenitiji pristup konstruiranju bloka sinteze uzima u obzir rezultirajuće pokazatelje pojedinih algoritama kao početne karakteristike za konstruiranje novog generaliziranog pravila odlučivanja. U ovom slučaju mogu se koristiti sve gore navedene metode intenzijskih i ekstenzijskih smjerova u prepoznavanju uzoraka. Učinkoviti za rješavanje problema kreiranja grupe pravila odlučivanja su logički algoritmi tipa “Kora” i algoritmi za izračunavanje procjena (ABO), koji čine osnovu tzv. algebarskog pristupa, koji omogućuje proučavanje i konstruktivan opis algoritmi za prepoznavanje, u čiji okvir se uklapaju sve postojeće vrste algoritama.
Komparativna analiza metoda prepoznavanja uzoraka
Usporedimo gore opisane metode prepoznavanja uzoraka i procijenimo stupanj njihove primjerenosti zahtjevima formuliranim u odjeljku 3.3.3 za SDA modele za adaptivne automatizirane upravljačke sustave za složene sustave.
Za rješavanje realnih problema iz skupine metoda intenzionog smjera praktičnu vrijednost imaju parametarske metode i metode temeljene na prijedlozima o obliku funkcija odlučivanja. Parametarske metode čine osnovu tradicionalne metodologije za konstruiranje pokazatelja. Primjena ovih metoda u stvarnim problemima povezana je s nametanjem jakih ograničenja na strukturu podataka, što dovodi do linearnih dijagnostičkih modela s vrlo grubim procjenama njihovih parametara. Pri korištenju metoda koje se temelje na pretpostavkama o obliku funkcija odlučivanja, istraživač je također prisiljen okrenuti se linearnim modelima. To je zbog visoke dimenzionalnosti prostora značajki, karakteristične za stvarne probleme, koji, kada se poveća stupanj polinomske funkcije odlučivanja, daje ogroman porast u broju svojih članova uz problematično popratno povećanje kvalitete prepoznavanja. Dakle, projiciranjem područja potencijalne primjene metoda intenzionalnog prepoznavanja na stvarne probleme, dobivamo sliku koja odgovara dobro razvijenoj tradicionalnoj metodologiji linearnih dijagnostičkih modela.
Svojstva linearnih dijagnostičkih modela, u kojima je dijagnostički pokazatelj predstavljen ponderiranim zbrojem početnih karakteristika, dobro su proučena. Rezultati ovih modela (uz odgovarajuću normalizaciju) tumače se kao udaljenosti od objekata koji se proučavaju do neke hiperravnine u prostoru značajki ili, ekvivalentno, kao projekcije objekata na neku ravnu liniju u tom prostoru. Stoga su linearni modeli primjereni samo jednostavnim geometrijskim konfiguracijama područja prostora značajki u koje se preslikavaju objekti različitih dijagnostičkih klasa. Sa složenijim distribucijama, ti modeli u osnovi ne mogu odražavati mnoge značajke strukture eksperimentalnih podataka. U isto vrijeme, takve značajke mogu pružiti vrijedne dijagnostičke informacije.
U isto vrijeme, pojavu jednostavnih višedimenzionalnih struktura (osobito višedimenzionalnih normalnih distribucija) u bilo kojem stvarnom problemu treba smatrati iznimkom, a ne pravilom. Često se dijagnostičke klase formiraju na temelju složenih vanjskih kriterija, što automatski povlači geometrijsku heterogenost tih klasa u prostoru značajki. To posebno vrijedi za “vitalne” kriterije, koji se najčešće susreću u praksi. Pod takvim uvjetima, korištenje linearnih modela hvata samo "najgrublje" obrasce eksperimentalnih informacija.
Korištenje ekstenzijskih metoda nije povezano s nikakvim pretpostavkama o strukturi eksperimentalnih informacija, osim da unutar prepoznatih klasa treba postojati jedna ili više skupina donekle sličnih objekata, a objekti različitih klasa trebaju se međusobno donekle razlikovati. Očito, za bilo koju konačnu veličinu uzorka za obuku (i ne može biti bilo koja druga), ovaj je zahtjev uvijek ispunjen jednostavno iz razloga što postoje slučajne razlike između objekata. Kao mjere sličnosti koriste se različite mjere blizine (udaljenosti) objekata u prostoru obilježja. Stoga učinkovita uporaba ekstenzijskih metoda prepoznavanja uzoraka ovisi o tome koliko su dobro određene specificirane mjere blizine, kao io tome koji objekti uzorka za obuku (objekti s poznatom klasifikacijom) služe kao dijagnostički presedani. Uspješno rješavanje ovih problema daje rezultate koji se približavaju teorijski dohvatljivim granicama učinkovitosti prepoznavanja.
Prednosti ekstenzijskih metoda prepoznavanja uzoraka suprotstavljaju se, prije svega, visokom tehničkom složenošću njihove praktične primjene. Za prostore značajki velikih dimenzija, naizgled jednostavan zadatak pronalaženja parova najbližih točaka postaje ozbiljan problem. Također, mnogi autori kao problem navode potrebu pamćenja dovoljno velikog broja objekata koji predstavljaju prepoznate klase.
To samo po sebi nije problem, ali se percipira kao problem (npr. u metodi k-najbližih susjeda) iz razloga što pri prepoznavanju svakog objekta dolazi do potpune pretrage svih objekata u skupu za treniranje.
Stoga je preporučljivo primijeniti model sustava prepoznavanja u kojem je otklonjen problem potpunog nabrajanja objekata u uzorku za obuku tijekom prepoznavanja, jer se ono provodi samo jednom prilikom generiranja generaliziranih slika klasa prepoznavanja. Tijekom samog prepoznavanja, identificirani objekt se uspoređuje samo s generaliziranim slikama klasa prepoznavanja, čiji je broj fiksan i potpuno neovisan o veličini uzorka za obuku. Ovaj pristup vam omogućuje povećanje veličine uzorka za obuku dok se ne postigne potrebna visoka kvaliteta generaliziranih slika, bez ikakve bojazni da bi to moglo dovesti do neprihvatljivog povećanja vremena prepoznavanja (budući da vrijeme prepoznavanja u ovom modelu ne ovisi o veličina uzorka za obuku uopće).uzorci).
Teorijski problemi korištenja metoda ekstenzijskog prepoznavanja povezani su s problemima traženja informativnih skupina obilježja, pronalaženja optimalne metrike za mjerenje sličnosti i razlika objekata te analize strukture eksperimentalnih informacija. U isto vrijeme, uspješno rješavanje ovih problema omogućuje ne samo konstruiranje učinkovitih algoritama za prepoznavanje, već i prijelaz s ekstenzivnog znanja o empirijskim činjenicama na intenziono znanje o obrascima njihove strukture.
Prijelaz iz ekstenzijskog u intenziono znanje događa se u fazi kada je formalni algoritam za prepoznavanje već konstruiran i njegova učinkovitost dokazana. Zatim se proučavaju mehanizmi kojima se postiže rezultirajuća učinkovitost. Takvo istraživanje, povezano s analizom geometrijske strukture podataka, može, primjerice, dovesti do zaključka da je dovoljno objekte koji predstavljaju određenu dijagnostičku klasu zamijeniti jednim tipičnim predstavnikom (prototipom). Ovo je ekvivalentno, kao što je gore navedeno, određivanju tradicionalne linearne dijagnostičke ljestvice. Također je moguće da je dovoljno zamijeniti svaku dijagnostičku klasu s nekoliko objekata, konceptualiziranih kao tipični predstavnici nekih potklasa, što je ekvivalentno konstruiranju lepeze linearnih ljestvica. Postoje i druge opcije o kojima će biti riječi u nastavku.
Stoga, pregled metoda prepoznavanja pokazuje da je sada teorijski razvijen niz različitih metoda prepoznavanja uzoraka. Literatura daje njihovu detaljnu klasifikaciju. Međutim, za većinu ovih metoda ne postoji programska implementacija, a to je duboko prirodno, moglo bi se čak reći i “predodređeno” karakteristikama samih metoda prepoznavanja. O tome se može suditi po tome što se takvi sustavi rijetko spominju u stručnoj literaturi i drugim izvorima informacija.
Posljedično, pitanje praktične primjenjivosti pojedinih teorijskih metoda prepoznavanja za rješavanje praktičnih problema sa stvarnim (tj. prilično značajnim) dimenzijama podataka i na stvarnim suvremenim računalima ostaje nedovoljno razrađeno.
Navedenu okolnost možemo razumjeti ako se prisjetimo da složenost matematičkog modela eksponencijalno povećava složenost programske implementacije sustava i u istoj mjeri smanjuje šanse da ovaj sustav praktično funkcionira. To znači da se u stvarnosti na tržištu mogu implementirati samo softverski sustavi koji se temelje na prilično jednostavnim i “transparentnim” matematičkim modelima. Stoga programer zainteresiran za repliciranje svog softverskog proizvoda pristupa pitanju odabira matematičkog modela ne sa čisto znanstvenog gledišta, već kao pragmatičar, uzimajući u obzir mogućnosti implementacije softvera. Smatra da model treba biti što jednostavniji, što znači da se treba implementirati s nižim troškovima i kvalitetnije, a mora i funkcionirati (biti praktički učinkovit).
U tom smislu, zadatak implementacije u sustave prepoznavanja mehanizma za generalizaciju opisa objekata koji pripadaju istoj klasi čini se posebno relevantnim, tj. mehanizam za formiranje kompaktnih generaliziranih slika. Očito, takav mehanizam generalizacije omogućit će "sažimanje" uzorka za obuku bilo koje dimenzije u bazu podataka generaliziranih slika unaprijed poznatih po dimenzijama. To će također omogućiti postavljanje i rješavanje brojnih problema koji se ne mogu niti formulirati u takvim metodama prepoznavanja kao što su metoda usporedbe s prototipom, metoda k-najbližih susjeda i ABO.
Ovo su zadaci:
- određivanje informacijskog doprinosa obilježja informacijskom portretu generalizirane slike;
- klaster-konstruktivna analiza generaliziranih slika;
- određivanje semantičkog opterećenja značajke;
- semantička klaster-konstruktivna analiza obilježja;
- smislena usporedba generaliziranih slika klasa međusobno i karakteristika međusobno (kognitivni dijagrami, uključujući Merlinove dijagrame).
Metoda koja je omogućila rješavanje ovih problema također razlikuje obećavajući sustav temeljen na njoj od drugih sustava, baš kao što se prevoditelji razlikuju od interpretatora, jer zahvaljujući formiranju generaliziranih slika u ovom obećavajućem sustavu, neovisnost vremena prepoznavanja od postiže se veličina uzorka za obuku. Poznato je da upravo postojanje ove ovisnosti dovodi do praktički neprihvatljivih troškova računalnog vremena za prepoznavanje u metodama kao što su metoda k-najbližih susjeda, ABO i KRP pri takvim dimenzijama uzorka za obuku kada se može govoriti o dovoljnoj statistici .
Za kraj kratkog pregleda metoda prepoznavanja, prikazat ćemo suštinu navedenog u zbirnoj tablici (tablica 3.1), koja sadrži kratak opis različitih metoda prepoznavanja uzoraka prema sljedećim parametrima:
- klasifikacija metoda prepoznavanja;
- područja primjene metoda prepoznavanja;
- klasifikacija ograničenja metoda prepoznavanja.
| Klasifikacija metoda prepoznavanja | Područje primjene | Ograničenja (nedostaci) | |
|---|---|---|---|
| Intenzivne metode prepoznavanja | Metode temeljene na procjenama gustoće distribucije vrijednosti obilježja (ili sličnosti i razlika objekata) | Problemi s poznatom distribucijom, obično normalnom, zahtijevaju veliku zbirku statistike | Potreba za nabrajanjem cijelog uzorka za obuku tijekom prepoznavanja, visoka osjetljivost na nereprezentativnost uzorka za obuku i artefakte |
| Metode temeljene na pretpostavkama o klasi funkcija odlučivanja | Klase moraju biti dobro odvojive, sustav obilježja mora biti ortonorman | Vrsta funkcije odlučivanja mora biti poznata unaprijed. Nemogućnost uzimanja u obzir novih spoznaja o korelacijama među svojstvima | |
| Booleove metode | Pri izboru logičkih pravila odlučivanja (konjunkcija) potrebna je potpuna pretraga. Visoka računalna složenost | ||
| Lingvističke (strukturne) metode | Problemi male dimenzije prostora značajke | Zadatak rekonstruiranja (definiranja) gramatike iz određenog skupa iskaza (opisa objekata) teško je formalizirati. Neriješeni teorijski problemi | |
| Metode ekstenzivnog prepoznavanja | Metoda usporedbe s prototipom | Problemi male dimenzije prostora značajke | Visoka ovisnost rezultata klasifikacije o mjeri udaljenosti (metrici). Nepoznata optimalna metrika |
| k metoda najbližih susjeda | Visoka ovisnost rezultata klasifikacije o mjeri udaljenosti (metrici). Potreba za potpunim popisom uzorka za obuku tijekom prepoznavanja. Računalni napor | ||
| Algoritmi za izračunavanje rejtinga (glasanja) AVO | Problemi malih dimenzija u smislu broja klasa i obilježja | Ovisnost rezultata klasifikacije o mjeri udaljenosti (metrici). Potreba za potpunim popisom uzorka za obuku tijekom prepoznavanja. Visoka tehnička složenost metode | |
| Kolektivi pravila odlučivanja (DRC) | Problemi malih dimenzija u smislu broja klasa i obilježja | Vrlo visoka tehnička složenost metode, neriješen niz teorijskih problema, kako u određivanju područja nadležnosti privatnih metoda, tako iu samim privatnim metodama. | |
Tablica 3.1 — Sažeta tablica klasifikacije metoda prepoznavanja, usporedba područja njihove primjene i ograničenja
Uloga i mjesto prepoznavanja uzoraka u automatizaciji upravljanja složenim sustavima
Automatizirani sustav upravljanja sastoji se od dva glavna dijela: objekta upravljanja i sustava upravljanja.
Kontrolni sustav obavlja sljedeće funkcije:
- identifikacija stanja kontrolnog objekta;
- razvoj kontrolnog djelovanja na temelju ciljeva upravljanja, uzimajući u obzir stanje objekta upravljanja i okoliša;
- osiguravanje upravljačkog utjecaja na objekt upravljanja.
Prepoznavanje uzoraka nije ništa drugo nego identificiranje stanja nekog objekta.
Posljedično, mogućnost korištenja sustava za prepoznavanje uzoraka u fazi identifikacije stanja kontrolnog objekta čini se sasvim očitom i prirodnom. Međutim, to možda neće biti potrebno. Stoga se postavlja pitanje u kojim slučajevima je preporučljivo koristiti sustav za prepoznavanje u sustavu automatiziranog upravljanja, au kojim nije.
Prema literaturi, mnogi dosad razvijeni i suvremeni automatizirani sustavi upravljanja u podsustavima za identifikaciju stanja objekta upravljanja i razvoj upravljačkih radnji koriste determinističke matematičke modele „izravnog proračuna“, koji nedvosmisleno i prilično jednostavno određuju što učiniti s upravljanjem. objekt ako ima određene vanjske parametre.
Pritom se ne postavlja niti rješava pitanje u kakvoj su vezi ti parametri s određenim stanjima objekta upravljanja. Ovo stajalište odgovara stajalištu da je "po defaultu" njihov odnos jedan na jedan prihvaćen. Stoga se pojmovi „parametri objekta upravljanja” i „stanje objekta upravljanja” smatraju sinonimima, a pojam „stanje objekta upravljanja” uopće se eksplicitno ne uvodi. Međutim, očito je da je u općem slučaju odnos između vidljivih parametara objekta upravljanja i njegovog stanja dinamičke i probabilističke prirode.
Prema tome, tradicionalni automatizirani sustavi upravljanja su u biti parametarski sustavi upravljanja, tj. sustavi koji ne upravljaju stanjima kontrolnog objekta, već samo njegovim vidljivim parametrima. Odluka o upravljačkoj radnji se u takvim sustavima donosi kao „na slijepo“, tj. bez formiranja cjelovite slike objekta upravljanja i okoline u njihovom trenutnom stanju, kao i bez predviđanja razvoja okoline i reakcije objekta upravljanja na određene upravljačke utjecaje na njega, djelujući istovremeno s predviđenim utjecajem okoline. .
Iz perspektive razvijene u ovom radu, pojam "odlučivanje" u modernom smislu teško da je u potpunosti primjenjiv na tradicionalne automatizirane upravljačke sustave. Činjenica je da “odlučivanje”, u najmanju ruku, pretpostavlja cjelovitu viziju objekta u okruženju, ne samo u njegovom trenutnom stanju, već iu dinamici, te u interakciji kako međusobno, tako i sa sustavom upravljanja, uključuje razmatranje različitih alternativnih opcija za razvoj cijelog ovog sustava, kao i sužavanje raznolikosti (redukcije) tih alternativa na temelju određenih ciljnih kriterija. Očito, ništa od toga se ne nalazi u tradicionalnim automatiziranim sustavima upravljanja, ili postoji, ali u pojednostavljenom obliku.
Naravno, tradicionalna metoda je primjerena i njezina je primjena sasvim ispravna i opravdana u slučajevima kada je objekt upravljanja uistinu stabilan i strogo determiniran sustav, a utjecaj okoline na njega se može zanemariti.
Međutim, u drugim slučajevima ova metoda je neučinkovita.
Ako je objekt upravljanja dinamičan, tada modeli na kojima se nalaze algoritmi upravljanja brzo postaju neadekvatni, jer se mijenjaju odnosi između ulaznih i izlaznih parametara, kao i sam skup bitnih parametara. U biti, to znači da su tradicionalni automatizirani sustavi upravljanja sposobni kontrolirati stanje upravljačkog objekta samo u blizini točke ravnoteže putem slabih upravljačkih djelovanja na njega, tj. metodom malih perturbacija. Daleko od stanja ravnoteže, s tradicionalnog gledišta, ponašanje upravljačkog objekta izgleda nepredvidljivo i nekontrolirano.
Ako ne postoji jednoznačna veza između ulaznih i izlaznih parametara upravljačkog objekta (tj. između ulaznih parametara i stanja objekta), drugim riječima, ako ta veza ima izraženu probabilističku prirodu, tada su deterministički modeli u kojima je pretpostaviti da je rezultat mjerenja određenog parametra samo broj, u početku nisu primjenjivi. Osim toga, vrsta te veze može jednostavno biti nepoznata i tada je potrebno poći od najopćenitije pretpostavke: da je ona vjerojatnosna ili da uopće nije određena.
Automatizirani sustav upravljanja izgrađen na tradicionalnim načelima može raditi samo na temelju parametara, čiji su obrasci veza već poznati, proučavani i reflektirani u matematičkom modelu. U ovoj studiji postavljen je zadatak razviti takve metode za projektiranje automatiziranih sustavi upravljanja koji će omogućiti stvaranje sustava sposobnih identificirati i najznačajnije parametre, te odrediti prirodu veza između njih i stanja objekta upravljanja.
U tom slučaju potrebno je koristiti razvijenije metode mjerenja koje su primjerene stvarnom stanju:
- klasifikacija ili prepoznavanje slika (učenje na temelju skupa za treniranje, prilagodljivost algoritama za prepoznavanje, prilagodljivost skupova klasa i parametara koji se proučavaju, odabir najznačajnijih parametara i smanjenje dimenzije opisa uz zadržavanje zadane redundancije, itd.);
- statistička mjerenja, kada rezultat mjerenja određenog parametra nije zaseban broj, već distribucija vjerojatnosti: promjena statističke varijable ne znači promjenu njezine vrijednosti same po sebi, već promjenu karakteristika distribucije vjerojatnosti njegove vrijednosti.
Kao rezultat toga, automatizirani sustavi upravljanja koji se temelje na tradicionalnom determinističkom pristupu praktički ne rade sa složenim dinamičkim višeparametarskim slabo određenim objektima upravljanja, kao što su, na primjer, makro- i mikro-društveno-ekonomski sustavi u dinamičnom gospodarstvu “ prijelazno razdoblje”, hijerarhijske elite i etničke skupine, društvo i biračko tijelo, ljudska fiziologija i psiha, prirodni i umjetni ekosustavi i mnogi drugi.
Vrlo je značajno da je sredinom 80-ih škola I. Prigoginea razvila pristup prema kojemu se u razvoju bilo kojeg sustava (uključujući i čovjeka) izmjenjuju razdoblja tijekom kojih se sustav ponaša ili kao "uglavnom deterministički" ili kao "uglavnom nasumičan". Naravno, stvarni upravljački sustav mora stabilno kontrolirati objekt upravljanja ne samo u "determinističkim" dionicama njegove povijesti, već iu točkama kada njegovo daljnje ponašanje postaje krajnje neizvjesno. Samo to znači da je potrebno razviti pristupe sustavima upravljanja čije ponašanje sadrži veliki element slučajnosti (ili onoga što se trenutno matematički opisuje kao "slučajnost").
Stoga će obećavajući automatizirani sustavi upravljanja koji osiguravaju upravljanje složenim dinamičkim višeparametarskim slabo determinističkim sustavima po svemu sudeći uključivati podsustave za identifikaciju i predviđanje stanja okoline i objekta upravljanja, temeljene na metodama umjetne inteligencije (prvenstveno prepoznavanje uzoraka), metodama podrške odlučivanju stvaranje i teorija informacija.
Razmotrimo ukratko pitanje korištenja sustava za prepoznavanje slika za donošenje odluka o upravljačkim radnjama (o ovom pitanju ćemo detaljnije govoriti kasnije, jer je ključno za ovaj rad). Ako ciljana i druga stanja upravljačkog objekta uzmemo kao klase prepoznavanja, a čimbenike koji utječu na njega kao značajke, tada se u modelu prepoznavanja uzoraka može oblikovati mjera odnosa između čimbenika i stanja. To omogućuje, za dano stanje upravljačkog objekta, dobivanje informacija o čimbenicima koji potiču ili ometaju njegov prijelaz u to stanje i, na temelju toga, razviti odluku o upravljačkoj akciji.
Čimbenici se mogu podijeliti u sljedeće skupine:
- karakteriziranje pozadine kontrolnog objekta;
- karakteriziranje trenutnog stanja kontrolnog objekta;
- okolišni čimbenici;
- tehnološki (kontrolirani) čimbenici.
Dakle, sustavi za prepoznavanje uzoraka mogu se koristiti kao dio automatiziranih upravljačkih sustava: u podsustavima za identifikaciju stanja upravljačkog objekta i razvoj upravljačkih akcija.
Ovo je prikladno kada je objekt upravljanja složen sustav.
Donošenje odluke o upravljačkoj akciji u sustavu automatiziranog upravljanja
Rješenje problema sintetiziranja adaptivnih automatiziranih sustava upravljanja složenim sustavima razmatra se u ovom radu, uzimajući u obzir brojne i duboke analogije između metoda prepoznavanja uzoraka i donošenja odluka.
S jedne strane, problem prepoznavanja uzoraka je donošenje odluke o tome pripada li prepoznati objekt određenoj klasi prepoznavanja.
S druge strane, autori predlažu da se problem donošenja odluka smatra inverznim problemom dekodiranja ili inverznim problemom prepoznavanja uzoraka (vidi odjeljak 2.2.2).
Zajedništvo osnovnih ideja na kojima se temelje metode prepoznavanja uzoraka i donošenja odluka postaje posebno očito kada ih se razmatra iz perspektive teorije informacija.
Raznolikost problema donošenja odluka
Odlučivanje kao ostvarenje cilja
Definicija: donošenje odluke (“izbor”) je djelovanje nad skupom alternativa, uslijed čega se početni skup alternativa sužava, tj. dolazi do njegove redukcije.
Izbor je radnja koja daje svrhu svim aktivnostima. Činovima izbora ostvaruje se podređivanje svih aktivnosti određenom cilju ili skupu međusobno povezanih ciljeva.
Dakle, da bi čin izbora postao moguć potrebno je sljedeće:
- stvaranje ili otkrivanje skupa alternativa na temelju kojih se mora napraviti izbor;
- određivanje ciljeva radi kojih se vrši izbor;
- razvoj i primjena metoda za međusobno uspoređivanje alternativa, tj. Određivanje ocjene preferencija za svaku alternativu prema određenim kriterijima koji omogućuju neizravnu procjenu koliko svaka alternativa odgovara cilju.
Suvremeni rad u području podrške odlučivanju otkrio je karakterističnu situaciju, a to je da je potpuna formalizacija pronalaženja najboljeg (u određenom smislu) rješenja moguća samo za dobro proučene, relativno jednostavne probleme, dok se u praksi slabo strukturirani problemi češće susreću, za koje nisu razvijeni nikakvi formalizirani algoritmi (osim iscrpnog pretraživanja i pokušaja i pogrešaka). Međutim, iskusni, kompetentni i sposobni stručnjaci često donose odluke koje se pokažu prilično dobrima. Stoga je suvremeni trend u praksi odlučivanja u prirodnim situacijama kombinirati ljudsku sposobnost rješavanja neformalnih problema sa mogućnostima formalnih metoda i računalnog modeliranja: interaktivni sustavi za potporu odlučivanju, ekspertni sustavi, prilagodljivi automatizirani sustavi upravljanja čovjek-stroj , neuronske mreže i kognitivni sustavi.
Odlučivanje kao otklanjanje neizvjesnosti (informacijski pristup)
Proces dobivanja informacija može se smatrati smanjenjem nesigurnosti kao rezultat prijema signala, a količina informacija može se smatrati kvantitativnom mjerom stupnja uklanjanja nesigurnosti.
Ali kao rezultat odabira određenog podskupa alternativa iz skupa, tj. kao rezultat donošenja odluka događa se ista stvar (smanjenje neizvjesnosti). To znači da svaki izbor, svaka odluka generira određenu količinu informacija, te se stoga može opisati u terminima teorije informacija.
Klasifikacija problema odlučivanja
Mnogostrukost zadataka odlučivanja posljedica je činjenice da se svaka komponenta situacije u kojoj se odlučuje može implementirati u kvalitativno različitim opcijama.
Nabrojimo samo neke od ovih opcija:
- skup alternativa, s jedne strane, može biti konačan, prebrojiv ili kontinuiran, a s druge strane zatvoren (tj. potpuno poznat) ili otvoren (uključujući nepoznate elemente);
- procjena alternativa može se provesti prema jednom ili više kriterija, koji pak mogu biti kvantitativne ili kvalitativne prirode;
- Način odabira može biti pojedinačni (jednokratni) ili višestruki, ponavljajući, uključujući povratnu informaciju o rezultatima izbora, tj. omogućavanje uvježbavanja algoritama za donošenje odluka uzimajući u obzir posljedice prethodnih izbora;
- posljedice odabira svake alternative mogu biti točno poznate unaprijed (izbor u uvjetima izvjesnosti), imaju probabilističku prirodu kada su poznate vjerojatnosti mogućih ishoda nakon izvršenog izbora (izbor u uvjetima rizika) ili imaju dvosmislen ishod s nepoznatim vjerojatnosti (izbor u uvjetima neizvjesnosti);
- odgovornost za izbor može biti odsutna, pojedinačna ili grupna;
- stupanj dosljednosti ciljeva u grupnom izboru može varirati od potpune podudarnosti interesa stranaka (kooperativni izbor) do njihove suprotnosti (izbor u konfliktnoj situaciji). Moguće su i međuvarijante: kompromis, koalicija, rastući ili blijedi sukob.
Razne kombinacije ovih opcija dovode do brojnih problema u donošenju odluka koji su proučavani u različitim stupnjevima.
Jezici za opisivanje metoda odlučivanja
O jednom te istom fenomenu može se govoriti na različitim jezicima s različitim stupnjevima općenitosti i primjerenosti. Do danas su se pojavila tri glavna jezika za opisivanje izbora.
Najjednostavniji, najrazvijeniji i najpopularniji je kriterijski jezik.
Jezik kriterija
Naziv ovog jezika povezuje se s osnovnom pretpostavkom da se svaka pojedinačna alternativa može vrednovati nekim određenim (jednim) brojem, nakon čega se usporedba alternativa svodi na usporedbu odgovarajućih brojeva.
Neka je, na primjer, (X) skup alternativa, a x neka specifična alternativa koja pripada tom skupu: x∈X. Tada se vjeruje da se za sve x može specificirati funkcija q(x), koja se naziva kriterijem (kriterij kvalitete, funkcija cilja, funkcija prednosti, funkcija korisnosti itd.), koja ima svojstvo da ako je alternativa x 1 poželjnija na x 2 (označeno: x 1 > x 2), tada je q(x 1) > q(x 2).
U ovom slučaju izbor se svodi na pronalaženje alternative s najvećom vrijednošću kriterijske funkcije.
Međutim, u praksi se korištenje samo jednog kriterija za usporedbu stupnja preferiranja alternativa pokazuje neopravdanim pojednostavljenjem, budući da detaljnije razmatranje alternativa dovodi do potrebe da se one vrednuju ne prema jednom, već prema više kriterija, koji mogu biti različite prirode i kvalitativno različiti jedni od drugih.
Primjerice, pri izboru najprihvatljivijeg tipa zrakoplova za putnike i organizaciju letenja na pojedinim vrstama ruta usporedbe se provode istovremeno prema više skupina kriterija: tehničkim, tehnološkim, ekonomskim, socijalnim, ergonomskim itd.
Višekriterijski problemi nemaju jedinstveno opće rješenje. Stoga se predlaže mnogo načina da se višekriterijskim problemima da određeni oblik koji omogućuje jedno opće rješenje. Naravno, ta su rješenja općenito različita za različite metode. Stoga je možda i najvažnija stvar u rješavanju višekriterijalnog problema opravdanost ovakve formulacije.
Za pojednostavljenje problema višekriterijalnog odabira koriste se različite mogućnosti. Nabrojimo neke od njih.
- Uvjetna maksimizacija (ne nalazi se globalni ekstrem integralnog kriterija, već lokalni ekstrem glavnog kriterija).
- Potražite alternativu s navedenim svojstvima.
- Pronalaženje Paretovog skupa.
- Svođenje višekriterijalnog problema na jednokriterijski problem uvođenjem integralnog kriterija.
Razmotrimo detaljnije formalnu formulaciju metode redukcije višekriterijskog problema na jednokriterijski.
Uvedimo integralni kriterij q 0 (x) kao skalarnu funkciju vektorskog argumenta:
q 0 (x) = q 0 ((q 1 (x), q 2 (x), ..., q n (x)).
Integralni kriterij vam omogućuje da poredate alternative prema vrijednosti q 0, ističući tako najbolje (u smislu ovog kriterija). Oblik funkcije q 0 određen je time koliko konkretno zamišljamo doprinos pojedinog kriterija integralnom kriteriju. Obično se koriste aditivne i multiplikativne funkcije:
q 0 = ∑a i ⋅q i /s i
1 - q 0 = ∏(1 - b i ⋅q i /s i)
Koeficijenti s i osiguravaju:
- Bezdimenzionalnost ili jednodimenzionalnost broja a i ⋅q i /s i (različiti parcijalni kriteriji mogu imati različite dimenzije i tada se nad njima ne mogu izvoditi aritmetičke operacije i svesti na integralni kriterij).
- Normalizacija, tj. osiguravajući uvjet: b i ⋅q i /s i<1.
Koeficijenti a i i b i odražavaju relativni doprinos parcijalnih kriterija q i integralnom kriteriju.
Dakle, u višekriterijskoj formulaciji problem donošenja odluke o izboru jedne od alternativa svodi se na maksimiziranje integralnog kriterija:
x * = arg max(q 0 (q 1 (x), q 2 (x), ..., q n (x)))
Glavni problem u višekriterijskoj formulaciji problema odlučivanja je što je potrebno pronaći takav analitički oblik koeficijenata a i b i koji bi osigurao sljedeća svojstva modela:
- visok stupanj primjerenosti predmetnom području i gledištu stručnjaka;
- minimalne računske poteškoće u maksimiziranju integralnog kriterija, tj. njegov izračun za različite alternative;
- stabilnost rezultata maksimiziranja integralnog kriterija od malih poremećaja početnih podataka.
- Stabilnost rješenja znači da mala promjena početnih podataka treba dovesti do male promjene vrijednosti integralnog kriterija, a time i do male promjene donesene odluke. Dakle, ako su početni podaci praktički isti, onda bi odluku trebalo donijeti ili istu ili vrlo blisku.
Jezik sekvencijalnog binarnog izbora
Jezik binarnih odnosa je generalizacija višekriterijalnog jezika i temelji se na uzimanju u obzir činjenice da je, kada procjenjujemo alternativu, ta ocjena uvijek relativna, tj. eksplicitno ili češće implicitno, druge alternative iz skupa koji se proučava ili iz opće populacije koriste se kao osnova ili referentni okvir za usporedbu. Ljudsko razmišljanje temelji se na traženju i analizi suprotnosti (konstrukta), pa nam je uvijek lakše izabrati jednu od dvije suprotne opcije nego jednu opciju iz velikog i nimalo uređenog skupa.
Dakle, osnovne pretpostavke ovog jezika su sljedeće:
- ne ocjenjuje se posebna alternativa, tj. ne uvodi se kriterijska funkcija;
- za svaki par alternativa može se na neki način utvrditi da je jedna od njih poželjnija od druge ili da su ekvivalentne ili neusporedive;
- odnos preferencija u bilo kojem paru alternativa ne ovisi o preostalim alternativama koje su predstavljene za izbor.
Postoje različiti načini specificiranja binarnih relacija: izravna, matrična, korištenje grafova preferencija, metoda presjeka itd.
Odnosi između alternativa jednog para iskazuju se kroz koncepte ekvivalencije, reda i dominacije.
Generalizirani jezik funkcije odabira
Jezik funkcije izbora temelji se na teoriji skupova i omogućuje vam rad s preslikavanjem skupova u njihove podskupove koji odgovaraju različitim izborima bez potrebe za nabrajanjem elemenata. Ovaj jezik je vrlo općenit i ima potencijal da opiše bilo koji izbor. Međutim, matematički aparat generaliziranih selekcijskih funkcija trenutno se još uvijek razvija i testira uglavnom na problemima koji su već riješeni uporabom kriterijskih ili binarnih pristupa.
Izbor grupe
Neka postoji grupa ljudi koja ima pravo sudjelovati u kolektivnom odlučivanju. Pretpostavimo da ova grupa razmatra određeni skup alternativa, a svaki član grupe donosi vlastiti izbor. Zadatak je razviti rješenje koje na određeni način koordinira individualne izbore i na neki način izražava “opće mišljenje” grupe, tj. prihvaćen kao grupni izbor.
Naravno, različitim grupnim odlukama odgovarat će različita načela usklađivanja pojedinačnih odluka.
Pravila za koordinaciju pojedinačnih odluka tijekom grupnog izbora nazivaju se pravilima glasovanja. Najčešće je “pravilo većine”, u kojem se alternativa s najviše glasova prihvaća kao grupna odluka.
Potrebno je shvatiti da takva odluka odražava samo prevladavanje različitih stajališta u skupini, a ne istinski optimalnu opciju, za koju nitko ne smije glasati. “Istina se ne utvrđuje glasanjem.”
Osim toga, postoje takozvani "paradoksi glasanja", od kojih je najpoznatiji Arrowov paradoks.
Ovi paradoksi mogu dovesti, a ponekad i dovode, do vrlo neugodnih značajki procedure glasovanja: na primjer, postoje slučajevi kada grupa uopće ne može donijeti niti jednu odluku (nema kvoruma ili svatko glasa za svoju jedinstvenu opciju, itd.). .), a ponekad (kod višestupanjskog glasovanja), manjina može nametnuti svoju volju većini.
Izbor u uvjetima neizvjesnosti
Izvjesnost je poseban slučaj neizvjesnosti, naime: to je nesigurnost blizu nule.
U modernoj teoriji izbora vjeruje se da postoje tri glavne vrste neizvjesnosti u problemima donošenja odluka:
- Informacijska (statistička) nesigurnost početnih podataka za odlučivanje.
- Neizvjesnost posljedica odlučivanja (izbora).
- Neodređenosti u opisu komponenti procesa odlučivanja.
Pogledajmo ih redom.
Informacijska (statistička) nesigurnost u izvornim podacima
Podaci dobiveni o predmetnom području ne mogu se smatrati apsolutno točnima. Osim toga, očito nam ti podaci nisu zanimljivi sami po sebi, već samo kao signali koji mogu nositi određene informacije o onome što nas stvarno zanima. Stoga je realnije smatrati da se radi o podacima koji nisu samo bučni i netočni, nego i neizravni, a možda i nepotpuni. Osim toga, ovi se podaci ne odnose na cjelokupnu populaciju koju proučavamo, već samo na njen određeni podskup, o kojem smo zapravo uspjeli prikupiti podatke, ali u isto vrijeme želimo izvući zaključke o cijeloj populaciji, a također žele znati stupanj pouzdanosti ovih zaključaka.
U tim uvjetima koristi se teorija statističkih odluka.
Dva su glavna izvora nesigurnosti u ovoj teoriji. Prvo, nije poznato kakvu distribuciju slijede izvorni podaci. Drugo, nepoznato je kakvu distribuciju ima skup (opća populacija) o kojem želimo izvući zaključke iz njegovog podskupa koji čini početne podatke.
Statistički postupci su postupci donošenja odluka koji uklanjaju obje ove vrste nesigurnosti.
Treba napomenuti da postoji niz razloga koji dovode do pogrešne primjene statističkih metoda:
- Statistički zaključci, kao i svaki drugi, uvijek imaju određenu pouzdanost ili valjanost. No, za razliku od mnogih drugih slučajeva, pouzdanost statističkih zaključaka poznata je i određena tijekom statističke studije;
- kvaliteta rješenja dobivenog primjenom statističkog postupka ovisi o kvaliteti izvornih podataka;
- podaci koji nemaju statističku prirodu ne smiju biti podvrgnuti statističkoj obradi;
- treba koristiti statističke postupke koji su prikladni za razinu apriornih informacija o populaciji koja se proučava (na primjer, metode ANOVA ne bi se trebale primjenjivati na ne-Gaussove podatke). Ako je raspodjela početnih podataka nepoznata, potrebno ju je ili utvrditi, ili koristiti više različitih metoda i usporediti rezultate. Ako se jako razlikuju, to ukazuje na neprimjenjivost nekog od korištenih postupaka.
Neizvjesnost posljedica
Kada su posljedice izbora jedne ili druge alternative nedvosmisleno određene samom alternativom, tada ne možemo razlikovati alternativu od njezinih posljedica, uzimajući zdravo za gotovo da odabirom alternative zapravo biramo njezine posljedice.
Međutim, u stvarnoj praksi često se moramo suočiti sa složenijom situacijom, kada izbor jedne ili druge alternative dvosmisleno određuje posljedice napravljenog izbora.
U slučaju diskretnog skupa alternativa i ishoda po njihovom izboru, pod uvjetom da je sam skup mogućih ishoda zajednički svim alternativama, možemo pretpostaviti da se različite alternative razlikuju jedna od druge u distribuciji vjerojatnosti ishoda. Te distribucije vjerojatnosti u općem slučaju mogu ovisiti o rezultatima izbora alternativa i stvarnim ishodima koji su rezultirali. U najjednostavnijem slučaju, ishodi su jednako vjerojatni. Sami ishodi obično imaju značenje dobitaka ili gubitaka i izraženi su kvantitativno.
Ako su ishodi jednaki za sve alternative, onda nema što birati. Ako su različite, tada možete usporediti alternative uvođenjem određenih kvantitativnih procjena za njih. Raznolikost problema u teoriji igara povezana je s različitim izborom numeričkih karakteristika gubitaka i dobitaka kao rezultat izbora alternativa, različitim stupnjevima sukoba između strana koje biraju alternative itd.
Ovu vrstu neizvjesnosti smatrajte nejasnom neizvjesnošću
Svaki zadatak izbora je zadatak ciljanog sužavanja skupa alternativa. I formalni opis alternativa (sam njihov popis, popis njihovih karakteristika ili parametara) i opis pravila za njihovu usporedbu (kriteriji, odnosi) uvijek se daju u smislu jedne ili druge mjerne ljestvice (čak i kada onaj tko radi ovo ne zna za ovo).
Poznato je da su sve ljuske zamagljene, ali u različitim stupnjevima. Pojam "zamagljivanje" odnosi se na svojstvo mjerila, koje se sastoji u činjenici da je uvijek moguće predstaviti dvije alternative koje se razlikuju, tj. različite na istoj ljestvici i nerazlučive, tj. identičan, u drugom - više zamagljen. Što je manje stupnjeva u određenoj ljestvici, to je ona zamućenija.
Dakle, možemo jasno vidjeti alternative i istovremeno ih nejasno klasificirati, tj. imaju neizvjesnost o tome kojoj klasi pripadaju.
Već u svom prvom radu o donošenju odluka u nejasnim situacijama, Bellman i Zadeh iznijeli su ideju da bi i ciljevi i ograničenja trebali biti predstavljeni kao neizraziti skupovi na skupu alternativa.
O nekim ograničenjima optimizacijskog pristupa
U svim problemima odabira i metodama donošenja odluka o kojima smo gore raspravljali, problem je bio pronaći one najbolje u izvornom skupu pod zadanim uvjetima, tj. alternative koje su u određenom smislu optimalne.
Ideja optimalnosti središnja je ideja kibernetike i čvrsto se ustalila u praksi projektiranja i rada tehničkih sustava. Istodobno, ova ideja zahtijeva pažljivo rukovanje kada je pokušavamo prenijeti na područje upravljanja složenim, velikim i slabo determiniranim sustavima, kao što su, primjerice, socioekonomski sustavi.
Postoje prilično dobri razlozi za ovakav zaključak. Pogledajmo neke od njih:
- Optimalno rješenje često se pokaže nestabilnim, tj. manje promjene u problemskim uvjetima, inputima ili ograničenjima mogu dovesti do odabira značajno različitih alternativa.
- Optimizacijski modeli razvijaju se samo za uske klase prilično jednostavnih problema, koji ne odražavaju uvijek adekvatno i sustavno stvarne objekte upravljanja. Najčešće optimizacijske metode omogućuju optimizaciju samo prilično jednostavnih i dobro formalno opisanih podsustava nekih velikih i složenih sustava, tj. dopustiti samo lokalnu optimizaciju. Međutim, ako svaki podsustav velikog sustava radi optimalno, to uopće ne znači da će sustav kao cjelina raditi optimalno. Stoga optimizacija podsustava ne mora nužno dovesti do ponašanja koje se od njega traži pri optimizaciji sustava kao cjeline. Štoviše, ponekad lokalna optimizacija može dovesti do negativnih posljedica za sustav u cjelini. Stoga je kod optimizacije podsustava i sustava u cjelini potrebno odrediti stablo ciljeva i podciljeva te njihov prioritet.
- Često se maksimiziranje kriterija optimizacije prema nekom matematičkom modelu smatra ciljem optimizacije, ali u stvarnosti cilj je optimizirati objekt upravljanja. Optimizacijski kriteriji i matematički modeli uvijek su povezani s ciljem samo neizravno, tj. više ili manje adekvatno, ali uvijek približno.
Dakle, ideja optimalnosti, koja je izuzetno plodna za sustave koji se mogu adekvatno matematički formalizirati, mora se s oprezom prenijeti na složene sustave. Naravno, matematički modeli koji se ponekad mogu predložiti za takve sustave mogu se optimizirati. Međutim, uvijek treba uzeti u obzir snažnu pojednostavljenost ovih modela, koja se u slučaju složenih sustava više ne može zanemariti, kao i činjenicu da je stupanj adekvatnosti ovih modela u slučaju složenih sustava gotovo nepoznat. . Stoga se ne zna kakav čisto praktični značaj ima ova optimizacija. Visoka praktičnost optimizacije u tehničkim sustavima ne bi trebala stvarati iluziju da će biti jednako učinkovita kod optimizacije složenih sustava. Smisleno matematičko modeliranje složenih sustava vrlo je teško, približno i netočno. Što je sustav složeniji, to trebate biti pažljiviji u pogledu njegove optimizacije.
Stoga, pri razvoju metoda za upravljanje složenim, velikim, slabo determinističkim sustavima, autori smatraju glavnom ne samo optimalnost odabranog pristupa s formalnog matematičkog gledišta, već i njegovu primjerenost cilju i samoj prirodi objekt upravljanja.
Ekspertne metode selekcije
Pri proučavanju složenih sustava često se javljaju problemi koji se iz različitih razloga ne mogu striktno formulirati i riješiti pomoću trenutno razvijenog matematičkog aparata. U tim slučajevima koriste se usluge stručnjaka (analitičara sustava) čije iskustvo i intuicija pomažu smanjiti složenost problema.
No, treba uzeti u obzir da su sami eksperti vrlo složeni sustavi, a njihovo djelovanje također ovisi o mnogim vanjskim i unutarnjim uvjetima. Stoga se u metodama organiziranja vještačenja velika pozornost posvećuje stvaranju povoljnih vanjskih i psiholoških uvjeta za rad vještaka.
Na rad stručnjaka utječu sljedeći čimbenici:
- odgovornost za korištenje rezultata ispita;
- saznanje da su uključeni i drugi stručnjaci;
- dostupnost informacijskog kontakta između stručnjaka;
- međuljudski odnosi stručnjaka (ako između njih postoji informacijski kontakt);
- osobni interes stručnjaka za rezultate procjene;
- osobne kvalitete stručnjaka (umišljenost, konformizam, volja i dr.)
Interakcija stručnjaka može potaknuti i potisnuti njihove aktivnosti. Stoga se u različitim slučajevima koriste različite metode ispitivanja koje se razlikuju po prirodi međusobne interakcije stručnjaka: anonimne i otvorene ankete i upitnici, sastanci, rasprave, poslovne igre, brainstorming itd.
Postoje različite metode matematičke obrade vještačenja. Od stručnjaka se traži da procijene različite alternative korištenjem jednog ili sustava pokazatelja. Osim toga, od njih se traži da procijene stupanj važnosti svakog pokazatelja (njegovu “težinu” ili “doprinos”). Samim stručnjacima također se dodjeljuje razina kompetencije koja odgovara doprinosu svakog od njih rezultirajućem mišljenju skupine.
Razvijena metodologija rada sa stručnjacima je Delphi metoda. Glavna ideja ove metode je da kritika i argumentacija imaju blagotvoran učinak na stručnjaka ako se ne utječe na njegov ponos i ako se osiguraju uvjeti koji isključuju osobnu konfrontaciju.
Posebno treba naglasiti da postoji temeljna razlika u prirodi korištenja ekspertnih metoda u ekspertnim sustavima iu podršci odlučivanju. Ako u prvom slučaju stručnjaci moraju formalizirati metode donošenja odluka, onda u drugom - samo samu odluku, kao takvu.
Budući da su stručnjaci uključeni u implementaciju upravo onih funkcija koje automatizirani sustavi trenutno ili uopće ne pružaju ili ih obavljaju lošije od ljudi, obećavajući smjer razvoja automatiziranih sustava je maksimalna automatizacija tih funkcija.
Automatizirani sustavi za podršku odlučivanju
Čovjek je oduvijek koristio pomoćnike pri donošenju odluka: to su bili jednostavno pružatelji informacija o objektu upravljanja, te konzultanti (savjetnici) koji su nudili mogućnosti odlučivanja i analizirali njihove posljedice. Čovjek koji donosi odluke uvijek ih je donosio u određenom informacijskom okruženju: za vojskovođu je to stožer, za rektora je to akademsko vijeće, za ministra je to kolegij.
Informacijska infrastruktura za donošenje odluka danas je nezamisliva bez automatiziranih sustava za interaktivnu procjenu odluka, a posebno sustava za podršku odlučivanju (DDS – Decision Support Systems), tj. automatizirani sustavi koji su posebno dizajnirani za pripremu informacija koje su osobi potrebne za donošenje odluke. Razvoj sustava za podršku odlučivanju provodi se, posebice, u okviru međunarodnog projekta koji se provodi pod pokroviteljstvom Međunarodnog instituta za primijenjenu analizu sustava u Laxenburgu (Austrija).
Donošenje odluka u situacijama stvarnog života zahtijeva niz operacija, od kojih neke učinkovitije izvode ljudi, a druge strojevi. Učinkovita kombinacija njihovih prednosti uz kompenzaciju nedostataka utjelovljena je u automatiziranim sustavima za podršku odlučivanju.
Čovjek odlučuje bolje od stroja u uvjetima neizvjesnosti, ali da bi donio ispravnu odluku potrebne su mu i odgovarajuće (potpune i pouzdane) informacije koje karakteriziraju predmetno područje. Međutim, poznato je da se ljudi ne nose dobro s velikim količinama “sirovih” neobrađenih informacija. Stoga uloga stroja u podršci odlučivanju može biti da izvrši preliminarnu pripremu informacija o objektu upravljanja i nekontroliranim čimbenicima (okolina), da pomogne u sagledavanju posljedica donošenja određenih odluka, kao i da sve te informacije prikaže u vizualnom obliku. i prikladan način za obrazac za donošenje odluka.
Stoga automatizirani sustavi za podršku odlučivanju kompenziraju slabosti osobe, oslobađaju je rutinske preliminarne obrade informacija i pružaju joj ugodno informacijsko okruženje u kojem može bolje pokazati svoje snage. Ovi sustavi nemaju za cilj automatizirati funkcije donositelja odluka (i posljedično otuđivati te funkcije od njega, a time i odgovornost za donesene odluke, što je često općenito neprihvatljivo), već mu pružiti pomoć u pronalaženju dobrog riješenje.
Općenito, mogu se razlikovati tri metode prepoznavanja uzoraka: Metoda grube sile. U ovom slučaju se radi usporedba s bazom podataka, gdje su za svaku vrstu objekta prikazane različite modifikacije prikaza. Na primjer, za optičko prepoznavanje uzoraka možete koristiti metodu nabrajanja izgleda objekta pod različitim kutovima, mjerilima, pomacima, deformacijama itd. Za slova morate nabrojati font, svojstva fonta itd. U slučaju prepoznavanja zvučne slike, sukladno tome, radi se usporedba s nekim poznatim obrascima (primjerice, riječ koju izgovori više ljudi).
Drugi pristup uključuje dublju analizu karakteristika slike. U slučaju optičkog prepoznavanja, to može biti određivanje različitih geometrijskih karakteristika. U ovom slučaju, uzorak zvuka podvrgava se analizi frekvencije, amplitude itd.
Sljedeća metoda je korištenje umjetnih neuronskih mreža (ANN). Ova metoda zahtijeva ili veliki broj primjera zadatka prepoznavanja tijekom obuke ili posebnu strukturu neuronske mreže koja uzima u obzir specifičnosti ovog zadatka. Međutim, nudi veću učinkovitost i produktivnost.
4. Povijest prepoznavanja uzoraka
Razmotrimo ukratko matematički formalizam prepoznavanja uzoraka. Objekt u prepoznavanju uzoraka opisuje se skupom osnovnih karakteristika (značajke, svojstva). Glavne karakteristike mogu biti različite prirode: mogu se uzeti iz uređenog skupa tipa prave linije ili iz diskretnog skupa (koji, međutim, također može biti obdaren strukturom). Ovo razumijevanje objekta je u skladu i s potrebom za praktičnom primjenom prepoznavanja uzoraka i s našim razumijevanjem mehanizma ljudskog opažanja predmeta. Doista, vjerujemo da kada osoba promatra (mjeri) neki objekt, informacije o njemu stižu preko konačnog broja senzora (analiziranih kanala) do mozga, a svaki senzor se može povezati s odgovarajućom karakteristikom objekta. Osim obilježja koja odgovaraju našim mjerenjima objekta, postoji i odabrano obilježje, odnosno skupina obilježja, koje nazivamo klasifikacijskim obilježjima, a pronalaženje njihovih vrijednosti za zadani vektor X zadatak je koji obavlja prirodni i umjetni sustavi prepoznavanja.
Jasno je da je za utvrđivanje vrijednosti ovih obilježja potrebno imati informacije o tome kako su poznata svojstva povezana s klasificirajućima. Informacije o ovoj vezi daju se u obliku presedana, odnosno skupa opisa objekata s poznatim vrijednostima klasifikacijskih karakteristika. I na temelju ovih informacija o presedanu, potrebno je konstruirati pravilo odlučivanja koje će proizvoljnom opisu objekta dodijeliti vrijednosti njegovih klasifikacijskih obilježja.
Ovakvo shvaćanje problema prepoznavanja uzoraka ustalilo se u znanosti od 50-ih godina prošlog stoljeća. A onda se primijetilo da takva produkcija nije nimalo nova. Susreli smo se sa sličnom formulacijom i već su postojale dosta dobro dokazane metode statističke analize podataka, koje su se aktivno koristile za mnoge praktične probleme, kao što je, na primjer, tehnička dijagnostika. Stoga su se prvi koraci prepoznavanja uzoraka odvijali u znaku statističkog pristupa koji je diktirao glavne probleme.
Statistički pristup temelji se na ideji da je izvorni prostor objekata vjerojatnosni prostor, a znakovi (karakteristike) objekata su slučajne varijable specificirane na njemu. Tada je zadatak data scientista bio da, na temelju određenih razmatranja, postavi statističku hipotezu o distribuciji obilježja, točnije, o ovisnosti klasificirajućih obilježja o drugima. Statistička hipoteza je u pravilu bila parametarski definiran skup funkcija raspodjele obilježja. Tipična i klasična statistička hipoteza je hipoteza o normalnosti ove distribucije (statističari su došli do velikog broja varijanti takvih hipoteza). Nakon formuliranja hipoteze, preostalo je ispitati tu hipotezu na prethodnim podacima. Ovaj test se sastojao od odabira određene distribucije iz inicijalno specificiranog skupa distribucija (parametar hipoteze distribucije) i procjene pouzdanosti (intervala pouzdanosti) tog izbora. Zapravo, ova funkcija raspodjele bila je odgovor na problem, samo što objekt više nije klasificiran jednoznačno, već s određenim vjerojatnostima pripadnosti klasama. Statističari su također razvili asimptotsko opravdanje za takve metode. Takva opravdanja napravljena su prema sljedećoj shemi: utvrđen je određeni funkcional za izbor kvalitete distribucije (interval pouzdanosti) i pokazano je da s povećanjem broja presedana naš izbor s vjerojatnošću koja teži 1 postaje točan u smisao ovog funkcionala (interval pouzdanosti teži 0). Gledajući unaprijed, reći ćemo da se statistički pogled na problem prepoznavanja pokazao vrlo plodonosnim ne samo u smislu razvijenih algoritama (koji uključuju metode klasterske i diskriminantne analize, neparametarske regresije itd.), nego i naknadno doveo do Vapnika do stvaranja duboke statističke teorije prepoznavanja .
Međutim, postoji jak argument da se problemi prepoznavanja uzoraka ne mogu svesti na statistiku. Svaki takav problem, u načelu, može se razmatrati sa statističke točke gledišta, a rezultati njegova rješenja mogu se statistički tumačiti. Da bi se to postiglo, potrebno je samo pretpostaviti da je objektni prostor problema probabilistički. Ali sa stajališta instrumentalizma, kriterij uspješnosti statističke interpretacije određene metode prepoznavanja može biti samo postojanje opravdanosti te metode u jeziku statistike kao grane matematike. Opravdanje ovdje podrazumijeva izradu osnovnih zahtjeva za zadatak koji osiguravaju uspjeh u primjeni ove metode. Međutim, u ovom trenutku za većinu metoda priznavanja, uključujući i one koje su izravno nastale u okviru statističkog pristupa, nisu pronađena takva zadovoljavajuća opravdanja. Osim toga, trenutačno najčešće korišteni statistički algoritmi, kao što je Fisherov linearni diskriminant, Parzenov prozor, EM algoritam, metoda najbližeg susjeda, da ne spominjemo Bayesove mreže vjerovanja, imaju izrazito heurističku prirodu i mogu imati tumačenja koja razlikuju od statističkih. I na kraju, svemu navedenom treba dodati da uz asimptotsko ponašanje metoda prepoznavanja, što je glavno pitanje statistike, praksa prepoznavanja postavlja pitanja računalne i strukturne složenosti metoda koja daleko nadilaze opseg same teorije vjerojatnosti.
Dakle, suprotno težnjama statističara da prepoznavanje uzoraka smatraju granom statistike, u praksu i ideologiju prepoznavanja uključene su sasvim druge ideje. Jedan od njih uzrokovan je istraživanjem u području vizualnog prepoznavanja uzoraka i temelji se na sljedećoj analogiji.
Kao što je već navedeno, u svakodnevnom životu ljudi stalno (često nesvjesno) rješavaju probleme prepoznavanja različitih situacija, slušnih i vizualnih slika. Takva mogućnost za računala je, u najboljem slučaju, stvar budućnosti. Stoga su neki pioniri prepoznavanja uzoraka zaključili da bi rješavanje tih problema na računalu trebalo, općenito govoreći, modelirati procese ljudskog mišljenja. Najpoznatiji pokušaj pristupa problemu iz ovog kuta bila je poznata studija F. Rosenblatta o perceptronima.
Do sredine 50-ih činilo se da su neurofiziolozi razumjeli fizičke principe mozga (u knjizi “The New Mind of the King” slavni britanski teorijski fizičar R. Penrose zanimljivo propituje model neuronske mreže mozga, opravdavajući značajnu ulogu kvantno-mehaničkih učinaka u njegovom funkcioniranju, iako je ovaj model od samog početka bio doveden u pitanje. Na temelju tih otkrića F. Rosenblatt je razvio model za učenje vizualnog prepoznavanja slika koji je nazvao perceptron. Rosenblattov perceptron predstavlja sljedeća funkcija (slika 1):
Slika 1. Perceptronski sklop
Na ulazu, perceptron prima objektni vektor, koji je u Rosenblattovu radu bio binarni vektor koji pokazuje koji je piksel na ekranu zacrnjen slikom, a koji nije. Zatim se svaki od znakova dovodi do ulaza neurona, čija je radnja jednostavno množenje s određenom težinom neurona. Rezultati se šalju posljednjem neuronu, koji ih zbraja i uspoređuje ukupnu količinu s određenim pragom. Ovisno o rezultatima usporedbe, ulazni objekt X se prepoznaje kao potreban ili ne. Tada je zadatak podučavanja prepoznavanja uzoraka bio odabrati težine neurona i vrijednosti praga kako bi perceptron dao točne odgovore na prethodne vizualne slike. Rosenblatt je vjerovao da bi rezultirajuća funkcija bila dobra u prepoznavanju željene vizualne slike čak i ako ulazni objekt nije među prethodnim. On je iz bioničkih razloga također smislio metodu odabira težina i pragova, na kojoj se nećemo zadržavati. Recimo samo da se njegov pristup pokazao uspješnim u brojnim problemima prepoznavanja i iznjedrio čitav smjer istraživanja algoritama učenja temeljenih na neuronskim mrežama, od kojih je poseban slučaj perceptron.
Nadalje, izumljene su razne generalizacije perceptrona, funkcija neurona je bila komplicirana: neuroni sada nisu mogli samo množiti ulazne brojeve ili ih zbrajati i uspoređivati rezultat s pragovima, već su na njih mogli primijeniti složenije funkcije. Slika 2 prikazuje jednu od ovih neuronskih komplikacija:

Riža. 2 Dijagram neuronske mreže.
Osim toga, topologija neuronske mreže mogla bi biti mnogo složenija od one koju je razmatrao Rosenblatt, na primjer ova:
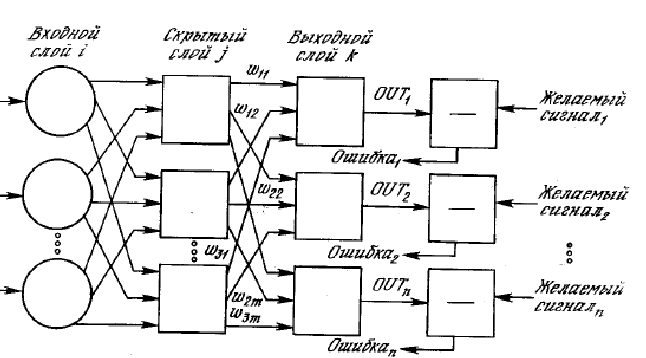
Riža. 3. Dijagram Rosenblatt neuronske mreže.
Komplikacije su dovele do povećanja broja podesivih parametara tijekom treninga, ali su u isto vrijeme povećale sposobnost ugađanja vrlo složenim obrascima. Istraživanja u ovom području sada se odvijaju u dva blisko povezana smjera - proučavaju se različite mrežne topologije i različite konfiguracijske metode.
Neuronske mreže trenutno nisu samo alat za rješavanje problema prepoznavanja uzoraka, već se također koriste u istraživanju asocijativne memorije i kompresije slike. Iako se ovo područje istraživanja snažno presijeca s problemima prepoznavanja uzoraka, ono predstavlja zasebnu granu kibernetike. Za prepoznavača u ovom trenutku, neuronske mreže nisu ništa drugo nego vrlo specifično definiran, parametarski definiran skup preslikavanja, koji u tom smislu nema značajnih prednosti u odnosu na mnoge druge slične modele učenja koji će biti ukratko navedeni u nastavku.
U vezi s ovom procjenom uloge neuronskih mreža za samo prepoznavanje (dakle, ne za bioniku, za koju su sada od najveće važnosti), želio bih napomenuti sljedeće: neuronske mreže, kao izuzetno složen objekt za matematičku analiza, kada se pravilno koristi, omogućuje pronalaženje vrlo netrivijalnih zakona u podacima. Njihova teškoća za analizu, općenito, objašnjava se njihovom složenom strukturom i, kao posljedicu, praktički neiscrpnim mogućnostima za generalizaciju širokog spektra obrazaca. No te su prednosti, kao što često biva, izvor potencijalnih pogrešaka i mogućnosti prekvalifikacije. Kao što će biti objašnjeno u nastavku, takav dvojni pogled na izglede bilo kojeg modela učenja jedno je od načela strojnog učenja.
Još jedan popularan smjer u prepoznavanju su logička pravila i stabla odlučivanja. U usporedbi s gore navedenim metodama prepoznavanja, ove metode najaktivnije koriste ideju izražavanja našeg znanja o predmetnom području u obliku vjerojatno najprirodnijih (na svjesnoj razini) struktura – logičkih pravila. Elementarno logičko pravilo znači izjavu poput "ako su neklasificirajuće značajke u odnosu X, onda su one klasificirane u odnosu Y." Primjer takvog pravila u medicinskoj dijagnostici je sljedeći: ako je pacijent stariji od 60 godina i prethodno je pretrpio srčani udar, tada nemojte izvoditi operaciju - rizik od negativnog ishoda je visok.
Za traženje logičkih pravila u podacima potrebne su dvije stvari: odrediti mjeru “informativnosti” pravila i prostor pravila. A zadatak traženja pravila tada se pretvara u zadatak potpunog ili djelomičnog nabrajanja u prostoru pravila kako bi se pronašlo najinformativnije od njih. Definicija informativnog sadržaja može se uvoditi na razne načine, na čemu se nećemo zadržavati, budući da je i to određeni parametar modela. Prostor pretraživanja definiran je na standardan način.
Nakon pronalaženja dovoljno informativnih pravila, započinje faza “sastavljanja” pravila u konačni klasifikator. Ne raspravljajući dublje o problemima koji se ovdje pojavljuju (a ima ih popriličan broj), navest ćemo 2 glavne metode "montaže". Prvi tip je linearna lista. Drugi tip je ponderirano glasovanje, kada se svakom pravilu dodjeljuje određena težina, a objekt klasifikator dodjeljuje klasi za koju je glasao najveći broj pravila.
Zapravo, faza konstrukcije pravila i faza "sastavljanja" izvode se zajedno i, kada se konstruira ponderirani glas ili popis, pretraživanje pravila na dijelovima podataka slučaja poziva se uvijek iznova kako bi se osiguralo bolje uklapanje između podataka i modela .
I znakovi. Takvi se problemi rješavaju prilično često, na primjer, prilikom prelaska ili prolaska ulice nakon semafora. Prepoznavanje boje upaljenog semafora i poznavanje pravila prometa omogućuje vam da donesete ispravnu odluku o tome možete li ili ne možete prijeći ulicu u ovom trenutku.
U procesu biološke evolucije mnoge su životinje probleme rješavale uz pomoć vizualnog i slušnog aparata. prepoznavanje uzorka dovoljno dobro. Stvaranje umjetnih sustava prepoznavanje uzorka ostaje složen teorijski i tehnički problem. Potreba za takvim prepoznavanjem javlja se u različitim područjima - od vojnih poslova i sigurnosnih sustava do digitalizacije svih vrsta analognih signala.
Tradicionalno, zadaci prepoznavanja uzoraka uključeni su u niz zadataka umjetne inteligencije.
Upute u prepoznavanju uzoraka
Mogu se razlikovati dva glavna pravca:
- Proučavanje sposobnosti prepoznavanja koje živa bića posjeduju, njihovo objašnjavanje i modeliranje;
- Razvoj teorije i metoda za konstruiranje uređaja za rješavanje pojedinačnih problema u primijenjenim primjenama.
Formalna izjava problema
Prepoznavanje uzoraka je dodjela izvornih podataka određenoj klasi identificiranjem značajnih obilježja koja karakteriziraju te podatke iz ukupne mase nevažnih podataka.
Pri postavljanju problema prepoznavanja nastoje koristiti matematički jezik, nastojeći, za razliku od teorije umjetnih neuronskih mreža, gdje je temelj dobivanje rezultata eksperimentom, eksperiment zamijeniti logičkim razmišljanjem i matematičkim dokazivanjem.
U problemima prepoznavanja uzoraka najčešće se razmatraju jednobojne slike, što omogućuje razmatranje slike kao funkcije na ravnini. Ako promatramo skup točaka na ravnini T, gdje je funkcija x(x,g) izražava svoje karakteristike u svakoj točki slike – svjetlinu, prozirnost, optičku gustoću, onda je takva funkcija formalni zapis slike.
Skup svih mogućih funkcija x(x,g) na površini T- postoji model skupa svih slika x. Predstavljamo koncept sličnosti između slika možete postaviti zadatak prepoznavanja. Konkretna vrsta takve izjave uvelike ovisi o kasnijim fazama prepoznavanja u skladu s jednim ili drugim pristupom.
Metode prepoznavanja uzoraka
Za optičko prepoznavanje uzoraka možete koristiti metodu pretraživanja kroz pogled na objekt pod različitim kutovima, mjerilima, odmacima itd. Za slova morate sortirati font, svojstva fonta itd.
Drugi pristup je pronaći obris objekta i ispitati njegova svojstva (povezanost, prisutnost kutova, itd.)
Drugi pristup je korištenje umjetnih neuronskih mreža. Ova metoda zahtijeva ili velik broj primjera zadatka prepoznavanja (s točnim odgovorima) ili posebnu strukturu neuronske mreže koja uzima u obzir specifičnosti ovog zadatka.
Perceptron kao metoda prepoznavanja uzoraka
F. Rosenblatt, uvodeći pojam modela mozga, čija je zadaća pokazati kako u nekom fizičkom sustavu, čija su struktura i funkcionalna svojstva poznata, mogu nastati psihički fenomeni – opisao je najjednostavnije eksperimenti diskriminacije. Ovi eksperimenti u potpunosti su povezani s metodama prepoznavanja uzoraka, ali se razlikuju po tome što algoritam rješenja nije deterministički.
Najjednostavniji eksperiment iz kojeg se može dobiti psihološki značajna informacija o određenom sustavu svodi se na činjenicu da se modelu prezentiraju dva različita podražaja i da se od njega traži da na njih odgovori na različite načine. Svrha takvog eksperimenta može biti proučavanje mogućnosti njihove spontane diskriminacije od strane sustava u nedostatku intervencije od strane eksperimentatora, ili, obrnuto, proučavanje prisilne diskriminacije, u kojoj eksperimentator nastoji uvježbati sustav da provesti traženu klasifikaciju.
U eksperimentu s treningom perceptrona obično se prikazuje određeni niz slika koji uključuje predstavnike svake od klasa koje treba razlikovati. Prema nekom pravilu modifikacije memorije, točan izbor odgovora je pojačan. Perceptronu se tada prezentira kontrolni podražaj i određuje se vjerojatnost dobivanja točnog odgovora za podražaje dane klase. Ovisno o tome podudara li se odabrani kontrolni podražaj ili ne s jednom od slika koje su korištene u sekvenci treninga, dobivaju se različiti rezultati:
- 1. Ako se kontrolni podražaj ne podudara ni s jednim od podražaja treninga, tada je eksperiment povezan ne samo s čista diskriminacija, ali uključuje i elemente generalizacije.
- 2. Ako kontrolni podražaj pobuđuje određeni skup osjetnih elemenata potpuno različitih od onih elemenata koji su se aktivirali pod utjecajem prethodno prezentiranih podražaja iste klase, tada je eksperiment studija čista generalizacija .
Perceptroni nemaju sposobnost čiste generalizacije, ali sasvim zadovoljavajuće funkcioniraju u eksperimentima razlikovanja, osobito ako se kontrolni podražaj dovoljno podudara s jednom od slika s kojima je perceptron već skupio neko iskustvo.
Primjeri problema prepoznavanja uzoraka
- Prepoznavanje slova.
- Prepoznavanje crtičnog koda.
- Prepoznavanje registarskih tablica.
- Prepoznavanje lica.
- Prepoznavanje govora.
- Prepoznavanje slike.
- Prepoznavanje lokalnih područja zemljine kore u kojima se nalaze nalazišta minerala.
Programi za prepoznavanje uzoraka
vidi također
Bilješke
Linkovi
- Jurij Lifšic. Kolegij “Suvremeni problemi teorijske informatike” - predavanja o statističkim metodama prepoznavanja uzoraka, prepoznavanja lica, klasifikacije teksta
- Časopis za istraživanje prepoznavanja uzoraka
Književnost
- David A. Forsythe, Jean Pons Računalni vid. Moderni pristup = Computer Vision: A Modern Approach. - M.: "Williams", 2004. - P. 928. - ISBN 0-13-085198-1
- George Stockman, Linda Shapiro Računalni vid = Computer Vision. - M.: Binom. Laboratorij znanja, 2006. - Str. 752. - ISBN 5947743841
- A.L.Gorelik, V.A.Skripkin, Metode prepoznavanja, M.: Viša škola, 1989.
- Š.-K. Cheng, Načela dizajna vizualnih informacijskih sustava, M.: Mir, 1994.
Zaklada Wikimedia. 2010.
- u tehnologiji, znanstveni i tehnički pravac povezan s razvojem metoda i konstrukcijom sustava (uključujući računalne) za utvrđivanje pripadnosti određenog objekta (predmeta, procesa, pojave, situacije, signala) nekom od naprednih ... ... Veliki enciklopedijski rječnikJedna od novih regija kibernetika. Sadržaj teorije R. o. je ekstrapolacija svojstava objekata (slika) koji pripadaju nekoliko klasa na objekte koji su im u nekom smislu bliski. Obično, kada trenirate automat R. o. dostupno... ... Geološka enciklopedija
Engleski prepoznavanje, slika; njemački Gestalt alterkennung. Grana matematičke kibernetike koja razvija principe i metode za klasificiranje i identificiranje objekata opisanih konačnim skupom značajki koje ih karakteriziraju. Antinazi. Enciklopedija...... Enciklopedija sociologije
Prepoznavanje uzorka- metoda proučavanja složenih objekata pomoću računala; sastoji se u odabiru značajki i razvoju algoritama i programa koji omogućuju računalima da automatski klasificiraju objekte na temelju tih značajki. Na primjer, odredite koji... ... Ekonomski i matematički rječnik
- (tehnički), znanstveni i tehnički smjer povezan s razvojem metoda i konstrukcijom sustava (uključujući računalne) za utvrđivanje pripadnosti određenog objekta (objekta, procesa, pojave, situacije, signala) jednom od naprednih ... ... enciklopedijski rječnik
PREPOZNAVANJE UZORKA- dio matematičke kibernetike koji razvija metode klasifikacije, kao i identifikacije objekata, pojava, procesa, signala, situacija svih onih objekata koji se mogu opisati konačnim skupom određenih znakova ili svojstava,... ... Ruska sociološka enciklopedija
prepoznavanje uzorka- 160 prepoznavanje uzoraka: Identificiranje oblika prikaza i konfiguracija korištenjem automatskih sredstava
Živi sustavi, pa tako i ljudi, od svoje su se pojave neprestano suočavali s problemom prepoznavanja uzoraka. Konkretno, informacije koje dolaze iz osjetila se obrađuju u mozgu, koji zauzvrat razvrstava informacije, osigurava donošenje odluka, a zatim pomoću elektrokemijskih impulsa prenosi potrebni signal dalje, primjerice, do organa za kretanje koji provode potrebne radnje. Tada se okolina mijenja, te se gore navedene pojave ponavljaju. A ako pogledate, svaku fazu prati prepoznavanje.
Razvojem računalne tehnologije postalo je moguće riješiti brojne probleme koji se javljaju u procesu života, olakšati, ubrzati i poboljšati kvalitetu rezultata. Na primjer, rad raznih sustava za održavanje života, interakcija čovjeka i računala, pojava robotskih sustava itd. No, napominjemo da trenutno nije moguće dati zadovoljavajući rezultat u nekim zadacima (prepoznavanje brzo pokretnih sličnih objekata). , rukom pisani tekst).
Svrha rada: proučavanje povijesti sustava za prepoznavanje slike.
Navesti kvalitativne promjene koje su se dogodile u području prepoznavanja uzoraka, teoretske i tehničke, uz navođenje razloga;
Razgovarati o metodama i principima koji se koriste u računalstvu;
Navedite primjere izgleda koji se očekuju u bliskoj budućnosti.
1. Što je prepoznavanje uzoraka?
Prvi studiji računalne tehnologije uglavnom su slijedili klasičnu shemu matematičkog modeliranja - matematički model, algoritam i proračun. To su bili zadaci modeliranja procesa koji se odvijaju tijekom eksplozija atomskih bombi, izračunavanja balističkih putanja, ekonomske i druge primjene. No, pored klasičnih ideja ovog niza, pojavile su se metode koje se temelje na sasvim drugoj prirodi, a kako je praksa rješavanja nekih problema pokazala, često su davale bolje rezultate od rješenja temeljenih na prekompliciranim matematičkim modelima. Njihova je ideja bila napustiti želju za stvaranjem iscrpnog matematičkog modela predmeta koji se proučava (štoviše, često je bilo gotovo nemoguće konstruirati odgovarajuće modele), i umjesto toga zadovoljiti se odgovorom samo na specifična pitanja koja nas zanimaju, te tražiti ove odgovore iz razmatranja zajedničkih za široku klasu problema. Istraživanja ove vrste uključivala su prepoznavanje vizualnih slika, predviđanje prinosa usjeva, vodostaja rijeka, zadatak razlikovanja naftonosnih i vodonosnih slojeva na temelju posrednih geofizičkih podataka itd. Konkretan odgovor u ovim zadacima zahtijevao se u prilično jednostavnom obliku, npr. , na primjer, pripada li objekt jednoj od unaprijed fiksnih klasa. A početni podaci ovih zadataka, u pravilu, dani su u obliku fragmentarnih informacija o predmetima koji se proučavaju, na primjer, u obliku skupa unaprijed klasificiranih objekata. S matematičke točke gledišta to znači da je prepoznavanje uzoraka (a tako se kod nas nazivala ova klasa problema) dalekosežna generalizacija ideje ekstrapolacije funkcija.
Važnost takve tvrdnje za tehničke znanosti je nesumnjiva, a to samo po sebi opravdava brojna istraživanja u ovom području. Međutim, problem prepoznavanja uzoraka ima i širi aspekt za prirodne znanosti (međutim, bilo bi čudno da nešto tako važno za umjetne kibernetičke sustave nema značenje za prirodne). Kontekst ove znanosti organski je uključivao i pitanja koja su postavili drevni filozofi o prirodi našeg znanja, našoj sposobnosti prepoznavanja slika, obrazaca i situacija u okolnom svijetu. Zapravo, malo je sumnje da su mehanizmi za prepoznavanje najjednostavnijih slika, poput slika opasnog grabežljivca ili hrane koji se približava, formirani puno prije pojave elementarnog jezika i formalnog logičkog aparata. I nema sumnje da su takvi mehanizmi prilično razvijeni kod viših životinja, koje također u svojim životnim aktivnostima hitno trebaju sposobnost razlikovanja prilično složenog sustava znakova prirode. Dakle, u prirodi vidimo da se fenomen mišljenja i svijesti jasno temelji na sposobnosti prepoznavanja slika, a daljnji napredak znanosti o inteligenciji u izravnoj je vezi s dubinom razumijevanja temeljnih zakona prepoznavanja. Razumijevajući činjenicu da gore navedeni problemi daleko nadilaze standardnu definiciju prepoznavanja uzoraka (u engleskoj literaturi češći je izraz nadzirano učenje), također je potrebno shvatiti da imaju duboke veze s ovim relativno uskim (ali ipak daleko od iscrpljenog) smjera.
Već sada je prepoznavanje uzoraka postalo sastavni dio svakodnevnog života i jedno je od najvažnijih znanja modernog inženjera. U medicini prepoznavanje uzoraka pomaže liječnicima u postavljanju točnijih dijagnoza; u tvornicama se koristi za predviđanje nedostataka u serijama robe. Biometrijski osobni identifikacijski sustavi kao njihova algoritamska jezgra također se temelje na rezultatima ove discipline. Daljnji razvoj umjetne inteligencije, posebice dizajn računala pete generacije sposobnih za izravniju komunikaciju s ljudima na ljudima prirodnim jezicima i putem govora, nezamisliv je bez priznanja. To je samo nekoliko koraka od robotike i umjetnih sustava upravljanja koji sadrže sustave prepoznavanja kao vitalne podsustave.
Zato je razvoj prepoznavanja uzoraka od samog početka izazvao veliku pozornost stručnjaka različitih profila - kibernetičara, neurofiziologa, psihologa, matematičara, ekonomista itd. Uvelike iz tog razloga je samo moderno prepoznavanje uzoraka potaknuto idejama ovih disciplina. Ne zahtijevajući cjelovitost (a to je nemoguće tvrditi u kratkom eseju), opisat ćemo povijest prepoznavanja uzoraka i ključne ideje.
Definicije
Prije nego što pređemo na glavne metode prepoznavanja uzoraka, predstavljamo nekoliko potrebnih definicija.
Prepoznavanje uzoraka (objekata, signala, situacija, pojava ili procesa) je zadaća identifikacije objekta ili utvrđivanja bilo kojeg svojstva na temelju njegove slike (optičko prepoznavanje) ili audio zapisa (akustičko prepoznavanje) i drugih karakteristika.
Jedan od osnovnih je pojam skupa koji nema konkretnu formulaciju. U računalu se skup predstavlja kao skup elemenata iste vrste koji se ne ponavljaju. Riječ "neponavljanje" znači da neki element u skupu ili postoji ili ga nema. Univerzalni skup uključuje sve moguće elemente za rješavanje problema, prazan skup ih ne sadrži.
Slika je klasifikacijska skupina u klasifikacijskom sustavu koja objedinjuje (ističe) određenu skupinu objekata prema određenom kriteriju. Slike imaju karakteristično svojstvo, koje se očituje u tome da upoznavanje konačnog broja pojava iz istog skupa omogućuje prepoznavanje proizvoljno velikog broja njegovih predstavnika. Slike imaju karakteristična objektivna svojstva u smislu da različiti ljudi, obučeni na različitom promatračkom materijalu, većinom klasificiraju iste objekte na isti način i neovisno jedan o drugom. U klasičnoj formulaciji problema prepoznavanja, univerzalni skup je podijeljen na dijelove slike. Svako preslikavanje objekta na perceptivne organe sustava za prepoznavanje, bez obzira na njegov položaj u odnosu na te organe, obično se naziva slika objekta, a skupovi takvih slika, ujedinjeni nekim zajedničkim svojstvima, su slike.
Metoda dodjele elementa bilo kojoj slici naziva se odlučujuće pravilo. Drugi važan koncept je metrika, način određivanja udaljenosti između elemenata univerzalnog skupa. Što je ta udaljenost manja, to su objekti (simboli, zvukovi itd.) sličniji onome što prepoznajemo. Tipično, elementi su navedeni kao skup brojeva, a metrika je navedena kao funkcija. Učinkovitost programa ovisi o izboru prikaza slike i implementaciji metrike; jedan algoritam za prepoznavanje s različitim metrikama činit će pogreške s različitim učestalostima.
Učenjem se obično naziva proces razvijanja u određenom sustavu jedne ili druge reakcije na skupine vanjskih identičnih signala kroz ponovljeno izlaganje sustavu vanjskih prilagodbi. Takve vanjske prilagodbe u treningu obično se nazivaju "nagrade" i "kazne". Mehanizam za generiranje ove prilagodbe gotovo u potpunosti određuje algoritam učenja. Samoučenje se razlikuje od treninga po tome što se ovdje ne daju dodatne informacije o ispravnosti reakcije na sustav.
Prilagodba je proces mijenjanja parametara i strukture sustava, a eventualno i upravljačkih radnji, na temelju trenutnih informacija kako bi se postiglo određeno stanje sustava u početnim nesigurnostima i promjenjivim uvjetima rada.
Učenje je proces kojim sustav postupno stječe sposobnost odgovoriti potrebnim reakcijama na određene skupove vanjskih utjecaja, a prilagodba je prilagodba parametara i strukture sustava radi postizanja potrebne kvalitete upravljanja. pred stalnim promjenama vanjskih uvjeta.
Primjeri zadataka prepoznavanja uzoraka: - Prepoznavanje slova;
- Tutorial
Dugo sam želio napisati općeniti članak koji će sadržavati same osnove prepoznavanja slike, neku vrstu vodiča za osnovne metode, govoreći kada ih koristiti, koje probleme rješavaju, što se može raditi navečer na koljenima i što je bolje ne razmišljati o tome bez tima od 20 ljudi.
Već dugo pišem neke članke o optičkom prepoznavanju, pa mi nekoliko puta mjesečno razni ljudi pišu s pitanjima na tu temu. Ponekad imate osjećaj da živite s njima u različitim svjetovima. S jedne strane, shvaćate da je osoba najvjerojatnije profesionalac u srodnoj temi, ali zna vrlo malo o metodama optičkog prepoznavanja. A ono što najviše smeta je što pokušava primijeniti metodu iz obližnjeg područja znanja, što je logično, ali ne radi u potpunosti u prepoznavanju slika, ali to ne razumije i jako se uvrijedi ako mu počnete govoriti nešto iz same osnove. A s obzirom na to da pričanje iz temelja oduzima puno vremena, kojeg često nema, postaje još tužnije.
Ovaj je članak namijenjen tako da osoba koja nikada nije radila s metodama prepoznavanja slika može u roku od 10-15 minuta stvoriti u svojoj glavi određenu osnovnu sliku svijeta koja odgovara temi i shvatiti u kojem smjeru treba kopati. Mnoge od ovdje opisanih tehnika primjenjive su na radarsku i audio obradu.
Počet ću s nekoliko principa koje uvijek počinjemo govoriti potencijalnom kupcu ili osobi koja se želi početi baviti optičkim prepoznavanjem:
- Kad rješavate problem, uvijek krenite od najjednostavnijeg. Mnogo je lakše staviti narančastu oznaku na osobu nego pratiti osobu, ističući je u kaskadama. Mnogo je lakše uzeti kameru veće rezolucije nego razviti algoritam super rezolucije.
- Stroga formulacija problema u metodama optičkog prepoznavanja mnogo je važnija nego u problemima sistemskog programiranja: jedna dodatna riječ u tehničkoj specifikaciji može dodati 50% posla.
- Ne postoje univerzalna rješenja za probleme prepoznavanja. Ne možete napraviti algoritam koji će jednostavno "prepoznati bilo koji natpis". Znak na ulici i list teksta bitno su različiti objekti. Vjerojatno je moguće napraviti opći algoritam (dobar primjer iz Googlea), ali će zahtijevati puno rada velikog tima i sastojat će se od desetaka različitih potprograma.
- OpenCV je biblija koja ima mnogo metoda i može riješiti 50% gotovo svakog problema, ali OpenCV je samo mali dio onoga što se zapravo može učiniti. U jednoj studiji zaključci su napisani: “Problem se ne može riješiti OpenCV metodama, stoga je nerješiv.” Pokušajte to izbjeći, nemojte biti lijeni i svaki put trezveno procijenite trenutni zadatak ispočetka, bez korištenja OpenCV predložaka.
Popis ovdje navedenih metoda nije potpun. Predlažem da u komentarima dodate kritičke metode koje nisam napisao i da svakoj pripišete 2-3 popratne riječi.
Dio 1. Filtriranje
U ovu sam grupu smjestio metode koje vam omogućuju odabir područja interesa na slikama bez njihove analize. Većina ovih metoda primjenjuje neku vrstu pojedinačne transformacije na sve točke na slici. Na razini filtriranja ne provodi se analiza slike, ali se točke koje se filtriraju mogu smatrati područjima s posebnim karakteristikama.Binarizacija po pragu, odabir područja histograma
Najjednostavnija transformacija je binarizacija slike prema pragu. Za RGB slike i slike u sivim tonovima, prag je vrijednost boje. Postoje idealni problemi u kojima je takva transformacija dovoljna. Pretpostavimo da želite automatski odabrati objekte na bijelom listu papira:

Odabir praga na kojem dolazi do binarizacije uvelike određuje sam proces binarizacije. U ovom slučaju, slika je binarizirana prosječnom bojom. Tipično, binarizacija se provodi pomoću algoritma koji adaptivno odabire prag. Takav algoritam može biti izbor očekivanja ili načina. Ili možete odabrati najveći vrh u histogramu.

Binarizacija može dati vrlo zanimljive rezultate pri radu s histogramima, uključujući i situaciju u kojoj ne razmatramo sliku u RGB, već u HSV. Na primjer, boje segmenta od interesa. Na ovom principu možete izgraditi i detektor oznaka i detektor ljudske kože.


Klasično filtriranje: Fourier, niskopropusni filtar, visokopropusni filtar
Klasične metode radarskog filtriranja i obrade signala mogu se uspješno primijeniti na razne zadatke prepoznavanja uzoraka. Tradicionalna metoda u radaru, koja se gotovo nikad ne koristi u slikama čistog oblika, je Fourierova transformacija (točnije, FFT). Jedna od rijetkih iznimaka u kojima se koristi jednodimenzionalna Fourierova transformacija je kompresija slike. Za analizu slike jednodimenzionalna transformacija obično nije dovoljna; trebate koristiti dvodimenzionalnu transformaciju koja zahtijeva mnogo više resursa.
Malo ljudi to zapravo izračuna; obično je mnogo brže i lakše koristiti konvoluciju područja interesa s gotovim filtrom, podešenim za visoke (HPF) ili niske (LPF) frekvencije. Ova metoda, naravno, ne dopušta analizu spektra, ali u specifičnom zadatku obrade videa obično nije potrebna analiza, već rezultat.


Najjednostavniji primjeri filtera koji naglašavaju niske frekvencije (Gaussov filter) i visoke frekvencije (Gaborov filter).
Za svaku točku slike odabire se prozor i množi s filtrom iste veličine. Rezultat takve konvolucije je nova vrijednost boda. Prilikom implementacije niskopropusnih filtara i visokopropusnih filtara dobivaju se slike sljedećeg tipa:


Valići
Ali što ako koristimo neku proizvoljnu karakterističnu funkciju za konvoluciju sa signalom? Tada će se zvati "Wavelet transformacija". Ova definicija valića nije točna, ali tradicionalno, u mnogim timovima, valićka analiza je potraga za proizvoljnim uzorkom na slici korištenjem konvolucije s modelom tog uzorka. Postoji skup klasičnih funkcija koje se koriste u valićnoj analizi. To uključuje valić Haar, valić Morlet, valić meksičkog šešira itd. Haar primitive, o kojima je bilo nekoliko mojih prethodnih članaka (,), odnose se na takve funkcije za dvodimenzionalni prostor.



Iznad su 4 primjera klasičnih valića. 3-dimenzionalni Haarov valić, 2-dimenzionalni Meyerov valić, meksički Hat valić, Daubechiesov valić. Dobar primjer korištenja proširene interpretacije valića je problem pronalaženja odsjaja u oku, za koji je valić sam odsjaj:

Klasični valići obično se koriste za ili za njihovu klasifikaciju (što će biti opisano u nastavku).
Poveznica
Nakon ovako slobodnog tumačenja valića s moje strane, vrijedno je spomenuti stvarnu korelaciju koja je u njihovoj osnovi. Ovo je nezamjenjiv alat pri filtriranju slika. Klasična primjena je korelacija video streama radi pronalaženja pomaka ili optičkih tokova. Najjednostavniji detektor pomaka također je, u određenom smislu, korelator razlike. Gdje slike nisu bile u korelaciji, bilo je kretanja.


Funkcije filtriranja
Zanimljiva klasa filtara je funkcionalno filtriranje. Ovo su čisto matematički filtri koji vam omogućuju otkrivanje jednostavne matematičke funkcije na slici (crta, parabola, krug). Konstruira se akumulirajuća slika u kojoj je za svaku točku izvorne slike nacrtan skup funkcija koje je generiraju. Najklasičnija transformacija je Hough transformacija za linije. U ovoj transformaciji, za svaku točku (x;y), nacrtan je skup točaka (a;b) pravca y=ax+b za koje vrijedi jednakost. Dobijate prekrasne slike:
(prvi plus ima onaj tko prvi nađe caku u slici i ovoj definiciji i objasni je, drugi plus ima onaj tko prvi kaže što je ovdje prikazano)
Houghova transformacija omogućuje pronalaženje bilo koje funkcije koja se može parametrizirati. Na primjer krugovi. Postoji modificirana transformacija koja vam omogućuje pretraživanje bilo kojeg . Matematičari užasno vole ovu transformaciju. Ali pri obradi slika, nažalost, ne radi uvijek. Vrlo spora brzina rada, vrlo visoka osjetljivost na kvalitetu binarizacije. Čak i u idealnim situacijama, radije sam se zadovoljio drugim metodama.
Analog Houghove transformacije za ravne linije je Radonova transformacija. Izračunava se putem FFT-a, što daje dobitak performansi u situaciji kada ima puno bodova. Osim toga, može se primijeniti na nebinariziranu sliku.
Filtriranje kontura
Zasebna klasa filtara je rubno i konturno filtriranje. Obrisi su vrlo korisni kada želimo prijeći s rada sa slikom na rad s objektima na toj slici. Kada je objekt prilično složen, ali jasno prepoznatljiv, tada je često jedini način rada s njim odabrati njegove konture. Postoji niz algoritama koji rješavaju problem filtriranja kontura:Najčešće se koristi Canny koji dobro radi i čija je implementacija u OpenCV-u (tu je i Sobel, ali lošije traži konture).


Ostali filteri
Iznad su filtri čije izmjene pomažu u rješavanju 80-90% problema. Ali osim njih, postoje rjeđi filtri koji se koriste u lokalnim zadacima. Postoji na desetke takvih filtera, neću ih sve nabrajati. Zanimljivi su iterativni filtri (na primjer), kao i ridgelet i curvlet transformacije, koje su spoj klasičnog valovitog filtriranja i analize u polju radon transformacije. Beamlet transformacija lijepo funkcionira na granici valićne transformacije i logičke analize, omogućujući vam da istaknete konture:
No te su transformacije vrlo specifične i skrojene za rijetke zadatke.
Dio 2. Logička obrada rezultata filtriranja
Filtriranje daje skup podataka prikladnih za obradu. Ali često ne možete jednostavno uzeti i koristiti te podatke bez obrade. U ovom odjeljku bit će nekoliko klasičnih metoda koje vam omogućuju prijelaz sa slike na svojstva objekata ili na same objekte.Morfologija
Prijelaz s filtriranja na logiku, po mom mišljenju, su metode matematičke morfologije (,). U biti, to su najjednostavnije operacije rasta i nagrizanja binarnih slika. Ove metode omogućuju uklanjanje šuma iz binarne slike povećanjem ili smanjenjem postojećih elemenata. Postoje algoritmi za konturiranje temeljeni na matematičkoj morfologiji, ali obično se koriste neke vrste hibridnih algoritama ili algoritama u kombinaciji.
Analiza kontura
Algoritmi za dobivanje granica već su spomenuti u odjeljku o filtriranju. Rezultirajuće granice se vrlo jednostavno pretvaraju u konture. Za Canny algoritam to se događa automatski; za druge algoritme potrebna je dodatna binarizacija. Možete dobiti konturu za binarni algoritam, na primjer, pomoću algoritma buba.Kontura je jedinstvena karakteristika objekta. To vam često omogućuje prepoznavanje objekta prema njegovom obrisu. Postoji moćan matematički aparat koji vam to omogućuje. Uređaj se naziva analiza kontura (,).

Da budem iskren, nikada nisam bio u mogućnosti primijeniti analizu kontura u stvarnim problemima. Potrebni su previše idealni uvjeti. Ili nema granica, ili je previše buke. Ali, ako trebate prepoznati nešto u idealnim uvjetima, onda je analiza kontura odlična opcija. Radi vrlo brzo, lijepa matematika i jasna logika.
Posebne točke
Singularne točke su jedinstvene karakteristike objekta koje omogućuju usporedbu objekta sa samim sobom ili sa sličnim klasama objekata. Postoji nekoliko desetaka načina za prepoznavanje takvih točaka. Neke metode identificiraju posebne točke u susjednim okvirima, neke nakon dužeg vremena i kada se osvjetljenje promijeni, neke vam omogućuju pronalaženje posebnih točaka koje ostaju takve čak i kada se objekt rotira. Počnimo s metodama koje nam omogućuju pronalaženje posebnih točaka, koje nisu tako stabilne, ali se brzo izračunavaju, a zatim ćemo ići u sve većoj složenosti:Prvi razred. Posebne točke koje su stabilne tijekom razdoblja od nekoliko sekundi. Takve se točke koriste za vođenje objekta između susjednih video okvira ili za kombiniranje slika sa susjednih kamera. Takve točke uključuju lokalne maksimume slike, kutove na slici (najbolji detektor je možda Charis detektor), točke u kojima se postiže maksimalna disperzija, određeni gradijenti itd.
Drugi razred. Posebne točke koje su stabilne pri promjenama osvjetljenja i malim pomacima objekta. Takve točke služe prvenstveno za obuku i kasniju klasifikaciju tipova objekata. Na primjer, klasifikator pješaka ili klasifikator lica proizvod je sustava izgrađenog upravo na takvim točkama. Neki od prethodno spomenutih valića mogu biti osnova za takve točke. Na primjer, Haar primitive, traženje istaknutih dijelova, traženje drugih specifičnih funkcija. Ove točke uključuju one koje su pronađene metodom histograma usmjerenih gradijenata (HOG).
Treća klasa. Stabilne točke. Znam samo za dvije metode koje daju potpunu stabilnost i njihove modifikacije. Ovo i . Omogućuju vam pronalaženje posebnih točaka čak i kada rotirate sliku. Izračun takvih bodova traje dulje u usporedbi s drugim metodama, ali je vrijeme prilično ograničeno. Nažalost, ove metode su patentirane. Iako je u Rusiji nemoguće patentirati algoritme, pa ga koristite za domaće tržište.
Dio 3. Trening
Treći dio priče bit će posvećen metodama koje ne rade izravno sa slikom, ali koje vam omogućuju donošenje odluka. U osnovi su to različite metode strojnog učenja i donošenja odluka. Yandyx je nedavno objavio na Habru na ovu temu, tamo ima jako dobar izbor. Evo ga u tekstualnoj verziji. Za ozbiljno proučavanje teme, toplo preporučujem da ih pogledate. Ovdje ću pokušati ocrtati nekoliko glavnih metoda koje se posebno koriste u prepoznavanju uzoraka.U 80% situacija suština učenja u zadatku prepoznavanja je sljedeća:
Postoji testni uzorak koji sadrži nekoliko klasa objekata. Neka to bude prisutnost/odsutnost osobe na fotografiji. Za svaku sliku postoji skup značajki koje su istaknute nekom značajkom, bilo da je to Haar, HOG, SURF ili neki valić. Algoritam učenja mora izgraditi model tako da može analizirati novu sliku i odlučiti koji je objekt na slici.
Kako se to radi? Svaka od testnih slika je točka u prostoru značajki. Njegove koordinate su težina svake značajke na slici. Neka naši znakovi budu: “Prisutnost očiju”, “Prisutnost nosa”, “Prisutnost dviju ruku”, “Prisutnost ušiju” itd... Sve ove znakove ćemo istaknuti pomoću naših postojećih detektora, koji su obučeni na dijelovi tijela slični ljudskim Za osobu u takvom prostoru točna bi točka bila . Za majmuna, točka za konja. Klasifikator se obučava pomoću uzorka primjera. Ali nisu sve fotografije prikazivale ruke, druge nisu imale oči, a na trećoj je majmun imao ljudski nos zbog pogreške klasifikatora. Istrenirani ljudski klasifikator automatski dijeli prostor značajki na takav način da kaže: ako je prva značajka u rasponu od 0,5




Postoji mnogo klasifikatora. Svaki od njih radi bolje u nekom određenom zadatku. Zadatak odabira klasifikatora za određeni zadatak uvelike je umjetnost. Evo nekoliko lijepih slika na temu.
Jednostavan slučaj, jednodimenzionalno razdvajanje
Pogledajmo primjer najjednostavnijeg slučaja klasifikacije, kada je prostor značajki jednodimenzionalan, a moramo razdvojiti 2 klase. Situacija se događa češće nego što mislite: na primjer, kada trebate razlikovati dva signala ili usporediti uzorak s uzorkom. Dopustite nam uzorak za obuku. Ovo proizvodi sliku gdje je X-os mjera sličnosti, a Y-os broj događaja s takvom mjerom. Kada je željeni objekt sličan sebi, dobiva se lijevi Gaussov. Kad ne izgleda tako – onaj pravi. Vrijednost X=0,4 razdvaja uzorke tako da pogrešna odluka smanjuje vjerojatnost donošenja pogrešne odluke. Potraga za takvim separatorom je zadatak klasifikacije.
Mala napomena. Kriterij koji minimizira pogrešku neće uvijek biti optimalan. Sljedeći grafikon je grafikon stvarnog sustava za prepoznavanje šarenice. Za takav sustav odabire se kriterij da se minimalizira vjerojatnost lažnog ulaska neovlaštene osobe u objekt. Ta se vjerojatnost naziva "pogreška tipa I", "vjerojatnost lažnog alarma", "lažno pozitivno". U literaturi na engleskom jeziku “False Access Rate”.
) AdaBusta je jedan od najčešćih klasifikatora. Na primjer, na njemu je izgrađena kaskada Haar. Obično se koristi kada je potrebna binarna klasifikacija, ali ništa ne sprječava obuku za veći broj klasa.
SVM ( , , , ) Jedan od najmoćnijih klasifikatora, koji ima mnogo implementacija. Uglavnom, na zadacima učenja s kojima sam se susretao, radio je slično kao Adabusta. Smatra se prilično brzim, ali njegovo je treniranje teže od Adabustinog i zahtijeva odabir prave jezgre.
Tu su i neuronske mreže i regresija. Ali da bismo ih ukratko klasificirali i pokazali u čemu se razlikuju, potreban nam je članak puno dulji od ovoga.
________________________________________________
Nadam se da sam uspio dati kratak pregled korištenih metoda bez poniranja u matematiku i opis. Možda ovo nekome pomogne. Iako je, naravno, članak nedorečen i nema ni riječi o radu sa stereo slikama, niti o LSM-u s Kalmanovim filtrom, niti o adaptivnom Bayesovom pristupu.
Ako vam se sviđa članak, pokušat ću napraviti drugi dio s izborom primjera kako se rješavaju postojeći problemi ImageRecognitiona.
I konačno
Što čitati?1) Jednom mi se jako svidjela knjiga "Digitalna obrada slike" B. Yanea, koja je napisana jednostavno i jasno, ali je u isto vrijeme data gotovo sva matematika. Dobro za upoznavanje s postojećim metodama.
2) Klasik žanra je R. Gonzalez, R. Woods “Digital Image Processing”. Iz nekog razloga bilo mi je teže od prvog. Puno manje matematike, ali više metoda i slika.
3) “Obrada i analiza slike u problemima računalnog vida” - napisano na temelju kolegija koji se izvodi na jednom od odsjeka za fiziku i tehnologiju. Postoji mnogo metoda i njihovih detaljnih opisa. Ali po mom mišljenju, knjiga ima dva velika nedostatka: knjiga je snažno usredotočena na softverski paket koji dolazi s njom; u knjizi se prečesto opis jednostavne metode pretvara u matematičku džunglu iz koje je teško izvesti strukturni dijagram metode. Ali autori su napravili prikladnu web stranicu na kojoj je predstavljen gotovo sav sadržaj - wiki.technicalvision.ru Dodaj oznake



